前回は、活性化関数がなぜ必要なのか、「活性化関数」で空間を歪めるものであると話をしました。

【仕組み解説】全結合層をゼロから実装しよう:活性化関数の導入(NN #5)
なぜ活性化関数が必要なのか?非線形性を導入し、全結合層の機能を最大限に引き出すための重要な役割と効果を解説します。
今回は、これまで学んできた多層パーセプトロンと活性化関数をどのように実装するのか、具体的に見ていこうと思います。
実装の観点では、ニューラルネットワークの層は、「線形変換を行う層(Affine)」と「非線形変換を行う層(活性化関数)」の2つをブロックのように交互に積み重ねて作ります。
その片割れである「全結合層(Affineレイヤー)」について、理解しましょう。
 11 記事
11 記事
ゼロから作る全結合層
ゼロから作る全結合層シリーズでは、初心者でも理解しやすいように、 「パーセプトロンの仕組み」から「全結合層の実装」までを...
この記事シリーズでは、ディープラーニングに入るまでの道筋をその根本的な設計思想からディープラーニングの肝であり、基礎の最小単位である全結合層について、ゼロから作って理解していきます。
全結合層(Affineレイヤー)とは何か?
前回の記事で説明した、ただの掛け算と足し算を担当するのがAffineレイヤーです。
パーセプトロンの時は \(x_1 w_1 + x_2 w_2 \dots\) と書いていましたが、入力が100個、1000個と増えたら式を書くのが大変ですよね。
そこで、行列(Matrix)を使います。
数式で書くと、こうなります。
\[Y = X \cdot W + B\]
- \(X\): 入力データ(行列)
- \(W\): 重み(行列)
- \(B\): バイアス(ベクトル)
- \(Y\): 出力データ(行列)
このたった一行の式で、何千何万というニューロンの計算を表せます。
これが数学の、そしてコンピュータの力の見せ所ですね。このような計算と処理に適しているのがGPU(グラフィックボード)なので、AIにはGPUが欠かせないいうわけです。
なぜ “Affine”レイヤー?
ディープラーニングのライブラリや論文では、全結合層のことをAffineレイヤーと呼ぶことがあります。なぜ「アフィン」なのでしょうか?
実はこの言葉、「画像処理(幾何学)」の世界からイメージすると正体がよく分かります。
画像を加工するソフトで「アフィン変換」という機能を聞いたことがありませんか?
(ペイントアプリで張り付けた画像を拡大縮小や移動させるイメージをしてみてください)
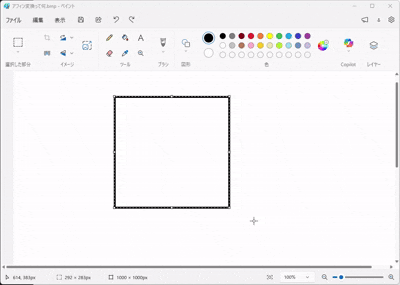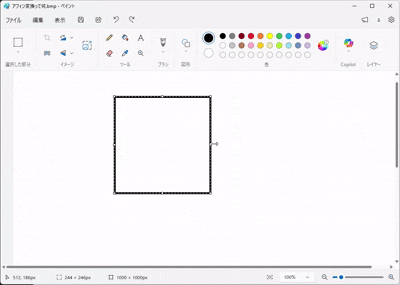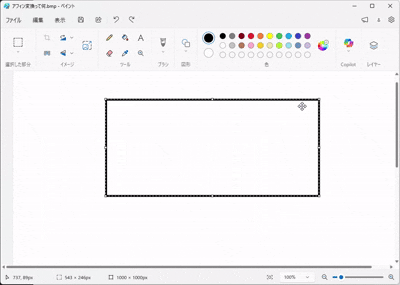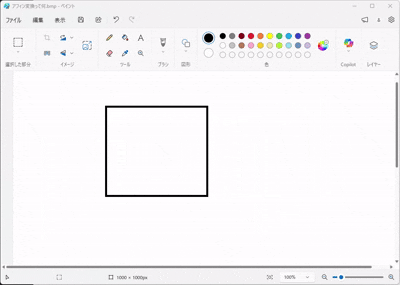
幾何学において、アフィン変換とは以下の2つを組み合わせた操作を指します。
- 線形変換(Linear): 画像を回転させたり、引き伸ばしたりする。(行列 \(W\) の役割)
- 平行移動(Translation): 画像を上下左右にズラす。(バイアス \(b\) の役割)
数式で見ると、全結合層の計算 \(y = Wx + b\) と全く同じ形をしていますね。
もし「バイアス(平行移動)」がないとどうなるでしょう?
画像は常に中心(原点)にピン留めされたまま、回転や拡大縮小しかできません。これでは、中心から離れた場所にあるデータにうまく合わせることができません。
「バイアス(\(+b\))」があるおかげで、データ(画像)を空間上の好きな位置へ「平行移動」させることができます。これらを合わせてアフィン変換と言い、これがちょうど全結合層の線形の計算と同じなのでアフィンレイヤーと呼ばれたりする訳ですね。
“Affine”自体の語源は、ラテン語で「類似」「関連」「境界を接する」「姻戚関係」などを意味する形容詞 「affinis」に由来するらしいです。
Affineレイヤーを行列(Matrix)で実装する方法を考える
アフィンレイヤーをもう少し実際の実装に近づけて考えてみます。
アフィンレイヤーに出てくる入力と重み、バイアスと出力のサイズは以下の様に書けます。
- 入力 : \(X: (N, D)\)
- 重み : \(W: (D, H)\)
- バイアス: \(B: (H)\)
- 出力 : \(Y: (N, H)\)
\(N, D, H\)の意味
- 入力データ数 \(N\): 3 一回の計算で扱うデータの数「バッチサイズ」のこと(初出なので後で説明します)
- 入力特徴量 \(D\): 4 前の層から伸びてくる入力線の本数(前の層のパーセプトロン数)
- 出力特徴量 \(H\): 3 この層のパーセプトロン数です。
これから順に計算していく手順を見てみます。
入力 \(X: (N, D)\) 例:\(X: (3, 4)\)
パーセプトロンの入力は今までの説明だと、2入力のXORを例としていたので 2つでしたが、パーセプトロンは複数の入力をもつことができます。
今回の例なら(D=4)なので、1つのパーセプトロンにつき4つの入力情報があります。バッチサイズは3としました。
\[ X = \begin{pmatrix} x_{11} & x_{12} & x_{13} & x_{14} \\ x_{21} & x_{22} & x_{23} & x_{24} \\ x_{31} & x_{32} & x_{33} & x_{34} \end{pmatrix}\]
N: バッチサイズって何?
バッチサイズとは、一回で計算するデータ数と言いましたが、これはどういうことでしょうか?
これまでは、1つのデータについて考えてきました。例えば、XORの(1,1)の組などのことです。これをX(N,D)の形に書くと、 X(1,2)となります。 2つの情報を持つデータ1つという意味になります。
バッチサイズ1で全体の計算を書いてみると以下のような感じになります。
\[\begin{pmatrix} y_{11} & y_{12} & y_{13} \end{pmatrix} = \begin{pmatrix} x_{11} & x_{12} & x_{13} & x_{14} \end{pmatrix} \cdot \begin{pmatrix} w_{11} \\ w_{21} \\ w_{31} \\ w_{41} \end{pmatrix} + \begin{pmatrix} b_{1} & b_{2} & b_{3} \end{pmatrix}\]
これを地道に1つ1つ計算していっても解けますが、それだと行列の便利な特性を生かせません、行列は一気に2本とか3本と言わず、100本、1000本の掛け算の計算をメモリの許す限り一気に計算できます。
ここでいう2本や3本、つまり、入力のデータの数をN、バッチサイズと言います。
全体のデータ数とは違うので注意して下さい。XORの例で考えてみると、XORで入力として受け取れる値(1と0ではない不定などを除く)は、0か1でしたね、この全パターンは(0,0)(0,1)(1,0),(1,1)で、これら全部を計算するとしたら、全体のデータ数は 4です。
これに対して、一回で2つずつ計算(バッチサイズ 2)とすると、
計算回数は \({4}\div{2} = 2\) 回となり、4回計算しなくてもよくなります。
重み \(W: (D, H)\) 例\(W: (4, 3)\)
上で書いた入力の入力特徴量 \(D = 4\)に掛け合わせる量で、出力のサイズに合わせて\(H = 3\)だけ並べる必要があります。
\[ W = \begin{pmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \\ w_{41} & w_{42} & w_{43} \end{pmatrix}\]
バイアス \(B: (H)\) 例\(B: (3)\)
出力のサイズに合わせて\(H = 3\)だけ並べる必要があります。
バイアスは出力に足すものなので、実際は、 \(B: (H,N)\)という風に出力と同じ形である必要があるので、バッチサイズ分だけ並べるほうが数式的には正しいですが、データによらず一定値を足す操作なので、式にすると以下の様になり、ごちゃごちゃするだけなので、一列に略して表記することが多いです。
丁寧に全部書いたとき
\[ \begin{pmatrix} b_{1} & b_{2} & b_{3}\\ b_{1} & b_{2} & b_{3}\\ b_{1} & b_{2} & b_{3} \end{pmatrix} \]
一般的に略して表記します。また、プログラム上でも、勝手にバッチサイズに合わせてくれるライブラリが多いです。
\[ \begin{pmatrix} b_{1} & b_{2} & b_{3} \end{pmatrix} \]
全体の式
アフィンレイヤーの計算を行列で書いたら以下のようになります。
\[Y = X \cdot W + B \]
\[\begin{pmatrix} y_{11} & y_{12} & y_{13} \\ y_{21} & y_{22} & y_{23} \\ y_{31} & y_{32} & y_{33} \end{pmatrix} = \begin{pmatrix} x_{11} & x_{12} & x_{13} & x_{14} \\ x_{21} & x_{22} & x_{23} & x_{24} \\ x_{31} & x_{32} & x_{33} & x_{34} \end{pmatrix} \cdot \begin{pmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \\ w_{41} & w_{42} & w_{43} \end{pmatrix} + \begin{pmatrix} b_{1} & b_{2} & b_{3} \end{pmatrix}\]
まとめと次回:活性化関数の主なものと全結合層
今回は、全結合層の線形部分の行列計算について、理解できたと思います。次回はこの出力に掛け合わせる活性化関数について主なものだけ触ってみようと思います。

【仕組み解説】全結合層をゼロから実装しよう:活性化関数-Reluとシグモイド関数-(NN #7)
頻繁に利用されるReLUとシグモイド関数の具体的な数式と役割を比較解説。逆伝播に向けた実装準備を行います。
11 記事
ゼロから作る全結合層
ゼロから作る全結合層シリーズでは、初心者でも理解しやすいように、 「パーセプトロンの仕組み」から「全結合層の実装」までを...
ここまで読んでいただきありがとうございます。
では、次の記事で。 lumenHero