1. はじめに
近赤外分光(NIR)スペクトルデータから、木材の含水率を予測するコンペティションに参加しました。
(比較的純粋な深層学習モデルでどこまで行けるのかをやってみたかったという動機が強いのでスコアはあまり良くないです、コンペ向けの手法が知りたい方は他サイトを参考にすることをお勧めします)
今回のコンペでは、汎化性を重視したモデルを構築し、最終的なPublicスコアは13~15付近に着地しました。しかし、この記事で共有したいのは単なるスコアや順位の話ではありません。深層学習と数値解析のアプローチを用いて、未知の樹種や個体に対する「真の汎化性能」をどのように追求したか、そのアーキテクチャ設計の軌跡をまとめます。(詳細については、規約上公開してもいいものか怪しかったので伏せていますご了承ください。)
~参加既約の抜粋~
1.参加者は、本コンペティションに関して当社から受領する情報、データ及びそれらを用いて得られた知見や生成物等(参加者の提出物を含み、以下「当社提供情報」といいます。)を秘密情報として取り扱い、第三者には開示しないものとし、かつ、本コンペティション及び別途当社が指定した目的以外に使用することができないものとします。 但し、以下の各号に定める情報は、秘密情報には含まれないものとします。
(1)受領の時点において公知となっていた情報
(2)受領の時点において、既に参加者が所有していた情報(当該参加者が合理的な手段で証明することができる場合に限ります。)
(3)受領の後に、参加者の責めによらず公知となった情報
(4)受領したいかなる情報にもよらずに独自に開発した情報
(5)何ら秘密保持義務を負担することなく開示権限ある第三者から合法的に受領した情報(当該参加者が合理的な手段でこれを証明することができる場合に限ります。)
手法自体は公知の手法であり、モデル構成のアイデア自体は私が考えたものなので問題ないので、その部分だけ共有できたらなと思います。グラフなどは手書きでそれっぽいものを配置しています。

SIGNATE
コンペサイト
competition-content.signate.jp2. コンペの概要と近赤外分光(NIR)の基本
モデルの複雑なアーキテクチャの話に入る前に、そもそもこの記事を読んでくださっている方に向けて「どんなデータを使って、何を予測しようとしていたのか」という前提を共有させてください。
2.1 そもそも近赤外分光(NIR)とは?
人間の目に見える光(可視光)の赤色よりも少し波長が長く、目には見えない光の領域を「近赤外線(Near-Infrared: NIR)」と呼びます。
物質にこの近赤外線を当てると、物質を構成する分子(特に水分に含まれるO-H結合や、有機物のC-H結合など)が、特定の波長の光を吸収してブルブルと振動します。 つまり、対象物に近赤外線を当てて「どの波長の光が、どれくらい吸収されたか(あるいは反射して返ってきたか)」を連続的なグラフ(スペクトル波形)にすることで、その物質の中に「どんな成分が、どれくらい含まれているか」を対象を破壊することなく、一瞬で推測することができるのです。
皆さんの身近なところでは、スーパーに並んでいる「糖度センサーで測った甘いみかん」なども、この近赤外分光の技術が使われています。農業、食品、製薬、そして今回の木材産業など、幅広い分野で実用化されている非常に強力なセンシング技術です。
画像1 NIRのスペクトルデータのイメージ
(含水率とか組成によって吸光度スペクトルに特徴的な山ができる。)
2.2 どんなデータから何を予測するコンペなのか?
今回のコンペティションの目的は、このNIRスペクトルデータを用いて「木材の含水率(内部にどれくらいの水分が含まれているか)」を予測するという回帰タスクでした。
木材の含水率は、建材としての強度や品質に直結します。水分が多すぎたり、乾燥ムラがあったりすると、後々になって家を支える柱が反り返ったり、割れたりする致命的な原因になります。そのため、木材工場では乾燥工程で正確に水分量を把握することが極めて重要なミッションとなります。
コンペで提供されたデータは、主に以下のような構成でした。
- 入力データ (X): 木材片に近赤外線を当てて計測された、細かな波長ごとの吸光度(スペクトル波形)。
- ターゲット (Y): その木材片の実際の含水率(%)。
- メタ情報: 個体ID(どの木材片か)、樹種ラベル(スギ、ヒノキ、コナラなどをイメージしてください、実際のデータにあったかどうかにかかわらず、説明の例としてこれらを使うことにします)。
この「光の波形データ」を入力し、正解である「水分量」を出力するAIを作る。一見するとよくある機械学習のタスクに見えますが、相手は工業製品ではなく、複雑な細胞構造を持つ自然物の「木材」です。
樹種ごとに異なるスペクトルからどのように水分量を正しく求めるのか?という部分が難しい部分です。
画像2 水分量や樹種毎の波形のイメージ
(手書きなのでたらめですが、樹種によって特徴があります。)
3. 過去モデル(Eシリーズ)の成功と「汎化」への疑念
コンペ中盤、水分吸収帯の波形を正確に捉えるために、画像認識で強力な性能を発揮するSqueeze-and-Excitation(SE)機構を組み込んだ1次元CNNモデル、通称「Eシリーズ(SEResBlockE)」を開発しました。(勝手にアルファベット順にシリーズ名をつけているだけなので、一般的な名称ではありません)
このモデルは学習データに対して高い適合力を示し、Public Leaderboard(暫定評価)では「7〜8」というスコアを出しました。(ターゲットが木材などの現実の物体なので、ある程度いい成果)
しかし、ここでひとつの重大な懸念が生まれます。 「このモデルは、本当に未知のデータに対しても機能する汎用性(汎化性能)を持っているのだろうか?」
検証のため、学習データから意図的に「特定の1樹種」を完全に隠して評価を行う、過酷な耐久テスト(Leave-One-Species-Out 交差検証)を実施しました。すると、Publicスコアでは一桁を誇っていたEシリーズの誤差(RMSE)が、未知の樹種に対しては一気に17〜30へと悪化しました。
つまり、Eシリーズは「手元にある樹種のパターンを暗記(過学習)」しているだけであり、木材の水分と光の反射が織りなす「普遍的な物理ルール」を真に理解しているわけではなかったのです。コンペの最終評価(Private Leaderboard)では完全に未知の個体や条件がテストされる可能性が高く、このままでは通用しないことが明白になりました。
4. 突破口:16次元の「樹種の指紋」によるドメイン適応
この「未知樹種に対する壁」を突破するための着想は、人間が便宜上付けた「スギ」「ヒノキ」といった離散的なラベルに頼るのではなく、スペクトル自体が持つ「連続的な物理特性(細胞壁の厚さや密度のグラデーション)」をモデルに理解させることでした。
そこで、回帰タスクの前に「樹種分類タスク」の事前学習を行い、木材のスペクトルから16次元の正規化された潜在ベクトル(ドメインの指紋)を自己抽出するエンコーダー(WoodDomainEncoder)を構築しました。
抽出した16次元の潜在空間をPCAで2次元に圧縮して可視化すると、非常に興味深い結果が得られました。
画像3 樹種の特徴:連続的な物理特性をベクトルに埋め込む
(イメージ図です、実際のデータとは異なります)
樹種ごとの特性が、潜在空間上でクラスタリングされ、かつ物理的な連続性を持っていることが確認できる。(紫は右上に集まっている+ある程度連続的な特徴を持っている)
このベクトル空間の地図を手に入れたことで、モデルは「この波形はスギとヒノキの中間のような物理特性を持っている」というメタ情報(ドメインの文脈)を自律的に獲得できるようになりました。
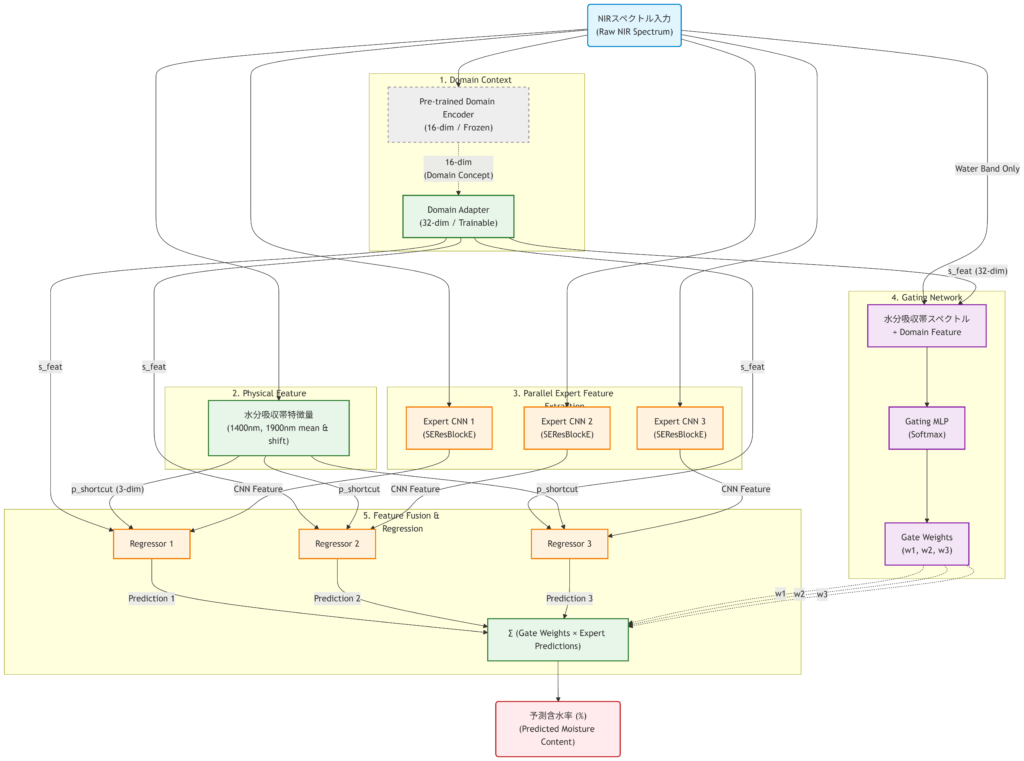
5. 最終アーキテクチャ:並列MoEフュージョン
抽出したメタ空間を実際の回帰タスクに適用するため、最終的に「並列MoE(Mixture of Experts)フュージョンアーキテクチャ」を設計しました。
アーキテクチャの核心は以下の通りです。
- Frozen Encoder + Trainable Adapter 事前学習した16次元エンコーダーの重みを「完全に凍結(Freeze)」します。その上で、16次元の指紋ベクトルを回帰タスク用のスケール(32次元)に翻訳するアダプター層のみを学習させます。
- Gating & MoE 水分吸収帯の「生の波形」と、翻訳された「樹種のコンテキスト」を組み合わせてゲートネットワークに入力し、3つの強力な高解像度CNN(Eシリーズで培ったSEResBlockE搭載のエキスパート)の出力を動的にブレンドします。
生の物理波形を1ミリも破壊することなく、樹種のコンテキスト(文脈)だけを補正係数としてノーリスクで合流(Fusion)させる。このWide & Deepな構造により、完全未知の木片に対する適応力を引き上げようと試みました。
6. 結果は?
結果を言うと、上位入賞とはいけませんでした。
いくつか試してみたものの中でそれなりにいいスコアを出せていたものもありました。しかし、提出ファイルを2つに絞らないといけないという制約から、パブリックスコア23とかを選択するような博打を打てなかったところが悔しいところですが、コンペなのでタラればは言ってもしかたないですね。
ほかの参加者の結果を聞く限りでも、パブリックおよびプライベート両方とも1桁代を出せていたのは一人だけ(提出ファイルは別)だったようなので、他の参加者も提出ファイル選択には苦慮されていたようです。
上位入賞者の前処理手法とかどんなアルゴリズムを使ったのかというところには興味があるので、上位入賞者の発表などを少し追ってみようかなと思っています。
7. コンペ特有の魔物と矜持
コンペティションの終了間際、一部の参加者から「リーダーボード・プロービング(LB Probing)」に関する言及がありました。これは、提出回数とスコア変動を利用して正解ラベルを逆算し、スプライン補間などを用いて高スコアを叩き出すハック手法です。
ルールの仕様上可能であったとはいえ、この手法で作られたモデルはデータサイエンスの本質とは異なり、現実の木材工場や計測機器へのデプロイには一切使えません。
今回、私が構築した「波形の物理的特徴」と「潜在空間の連続性」を統合するモデルは、スコアの穴を突いたものではなく、物理原則に則った堅牢なシステムです。(を目指して構築してみました)
精度的には一歩足りなかったものの、DLモデルなので測定したデータを増やした分だけ精度を上げられるというスケーリングができるモデルにできたのではないかなと思います。
8.謝辞
深層学習や数値解析をメインで研究している身として常々痛感するのは、「モデルの最終的なポテンシャルは、入力される一次情報の正確さと精密さに完全に依存する」という残酷なまでの真理です。
どんなに高度な並列MoEアーキテクチャを構築し、ドメイン適応のための精緻な数理モデルを組んだとしても、土台となるスペクトルデータがノイズまみれであったり、測定条件がデタラメであれば、AIが物理法則を学習することは絶対に不可能です。
今回、物理現象に則ったモデルを完成させることができたのは、ひとえに提供されたデータセットが圧倒的に高品質だったからです。
最後に、このような非常に挑戦的で意義深いコンペティションを開催していただいた運営の皆様、そして何より、我々データサイエンティストの探求の根幹を支える、極めて精密な測定結果をご提供いただいた近赤外研究会の皆様に、深い敬意と心からの謝辞を申し上げます。
本質的なデータ構造と正面から向き合うことができた、非常に有意義な数週間でした。
(執筆:LumenHero, 2026/07/01)

