前回は、全結合層の線形部分について、行列でどのように表すのかを紹介しました。

【仕組み解説】全結合層をゼロから実装しよう:全結合層とは?-アフィンレイヤー-(NN #6)
全結合層を数学的に扱うための概念、アフィンレイヤーを解説。NNの「層」の順伝播処理をゼロから理解します。
今回は、#5で紹介したように、線形部分に掛け合わせて非線形性を持たせる活性化関数について、その主なもの sgmoid関数とRelu関数について、その特性を見てみようと思います。
 11 記事
11 記事
ゼロから作る全結合層
ゼロから作る全結合層シリーズでは、初心者でも理解しやすいように、 「パーセプトロンの仕組み」から「全結合層の実装」までを...
この記事シリーズでは、ディープラーニングに入るまでの道筋をその根本的な設計思想からディープラーニングの肝であり、基礎の最小単位である全結合層について、ゼロから作って理解していきます。
シグモイドとReluに入る前に、
非線形を持たせるために活性化関数を用いるとこれまで説明してきましたが、一番初めに取り扱ったXOR問題の時のANDやORの非線形関数ステップ関数(0より大きかったら”1″,小さかったら “0”とする関数)について、そのグラフなどを見てみます。
\[
output =
\begin{cases}
1 & (y > 0) \\
0 & (y \le 0)
\end{cases}
\]
これを見れば、この後紹介する、シグモイド関数やRelu関数がなぜ使われているか理解しやすいはずです。
1. 古い関数:ステップ関数
ステップ関数
\[
y =
\begin{cases}
1 & (x > 0) \\
0 & (x \le 0)
\end{cases}
\]
をグラフにしてみると以下のようなグラフになります。
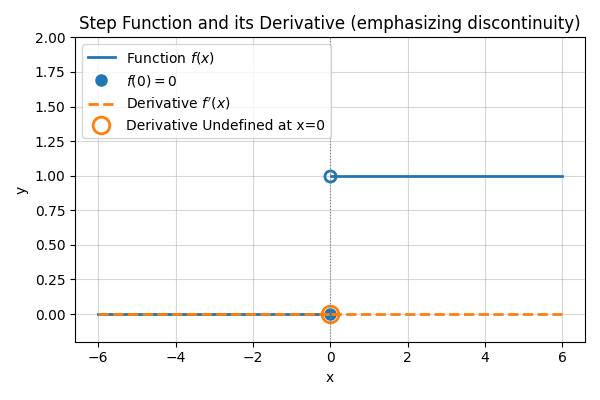
ステップ関数のグラフ
0を境に0と1と出力(y)を切り替えるような関数なので、非線形な関数であるとわかります。
ステップ関数は単純な関数なので、便利そうですが、ニューラルネットワークの活性化関数として使うには大きな欠点があります。それは微分値がほぼすべての場所で”0″であり、ちょうど値が切り替わる0の地点では、定義不可能なことです。
【微分のグラフ(致命的な弱点)】
このグラフの「傾き」を考えてみてください。
- 平らな部分(\(x \neq 0\))の傾きはすべて 「0」 です。
- 切り替わる瞬間(\(x = 0\))は、垂直に切り立っているので微分できません(あるいは無限大)。
なぜダメなのか?
NNの学習(バックプロパゲーション この先の記事で紹介します。)では、「傾き」を使って重みを少しずつ修正します。
しかし、傾きがずっと「0」だと、「どっちに動いても変化しないよ」と言われているのと同じで、学習が一切進まないんです。
これが、単層パーセプトロンからニューラルネットワークへ進化する際に、ステップ関数が捨てられた理由です。
2. シグモイド関数(Sigmoid Function)
NNの活性化関数では、ステップ関数は使えなそうです。でも、どうにか似た形の関数で微分可能なものが必要でした、そこで登場したのが、自然界の滑らかさを模したシグモイド関数です。
シグモイド関数
\[ h(x) = \frac{1}{1 + \exp(-x)}\]
これをグラフにしてみると以下のようになります。
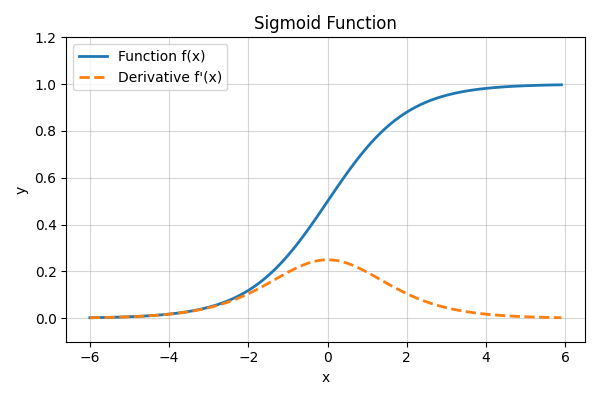
シグモイド関数のグラフ
グラフを見ると、シグモイド関数自体は、0から1に滑らかに動いていく関数であることがわかると思います。形だけを見るとステップ関数に似ていますね。
【微分のグラフ(弱点あり)】
傾きを見ると、滑らかな変化なので、0で不定になったりせず、傾きも滑らかになっていることがわかります。この傾きは、0のところで 0.25 (\( \frac{1}{4} \))となっています。
- 傾きが「0」ではないため、学習の信号(誤差)をちゃんと伝えることができます。
「今は0.3くらい間違ってるから、こっちに修正して!」という指示が通るようになったわけです。
ただ、入力が大きすぎたり小さすぎたりすると、グラフの端っこで傾きが再び「0」に近づいてしまう(勾配消失問題)という、新たな影も持っています。
また、最大値が 0.25なので、層を重なれれば重ねるほど受け渡せる特徴量を小さくしてしまい、深い層にすると学習できないという問題もありました。
最近の利用用途としては、2値分類とかの出力手前で部分的に使うなどの用途がメインです。
最近の主流:ReLU関数 (Rectified Linear Unit)
今、最も使われているのがReLU(レル)です。
シグモイドは計算が複雑(\(e\)の計算が必要)で、層を深くすると学習しづらくなる弱点がありました。そこで、「もっとシンプルでいいじゃないか」と生まれたのがこれです。
ReLU関数
\[h(x) = \begin{cases} x & (x > 0) \\ 0 & (x \le 0) \end{cases}\]
グラフにしてみると以下のような感じです
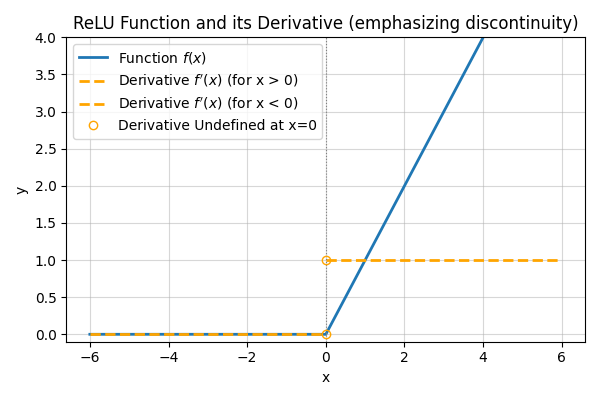
Relu関数のグラフ
グラフを見ると、0以下は全部0になって、0以上はxをそのまま出力していることがわかります。
【微分のグラフ】
このグラフの「傾き」を考えてみると、ちょうどステップ関数になっていますね。
- \(x > 0\) のとき:傾きは常に 「1」。
- \(x \le 0\) のとき:傾きは常に 「0」。
非常にシンプルですが、これが強力なんです。
プラスの領域では、傾きが「1」のまま減衰しないので、層を深くしても学習の情報が消えにくい(勾配消失しにくい)。しかも計算がめちゃくちゃ速いというメリットがあります。
ReLUの「角」を削る? 最近の活性化関数事情
= ReLUの弱点? 「0」の不連続性 =
ステップ関数の微分の欠点として「0で値が計算できない(微分不可能)」ことを挙げました。 では、現代の主役であるReLUはどうでしょう? 実はReLUも、\(x=0\) の地点でグラフが折れ曲がっており、数学的には微分が連続ではありません。
なぜ普段は問題にならないのか
通常の分類タスクなどでは、これは大きな問題になりません。実装上、$x=0$ の時の微分値を便宜的に「0(または1)」と決めてしまうことで、計算を止めずに学習を進められるからです(これを劣微分を用いた対処と呼びます)。また、計算中に数値が「完全に0」になる確率は非常に低いため、無視できることが多いのです。
= 繊細なモデルに必要な「滑らかさ」=
しかし、画像生成AIや大規模言語モデル(LLM)など、出力のわずかな変化が品質に直結する繊細なモデルでは、ReLUの「0での急激な切り替わり」が学習の精度を下げてしまうことがあります。
そこで近年注目されているのが、ReLUとシグモイド関数を組み合わせたような、「Swish (SiLU)」や「GELU」といった関数です。これらはReLUの良さを持ちつつ、0付近が滑らかな曲線になっており、より複雑で自然な表現が可能になります。
興味があれば「Swish関数」や「GELU」について調べてみると、AIの進化の最前線が見えてくるかもしれません。

脱ReLU!敵対的学習では、滑らかな活性化関数を使うべし!
Reluを改良した関数の論文紹介
ai-scholar.tech筆者メモ:シグモイドのような滑らかさを持つReluなので SigmoReluなんて呼び方を少し前までされたりしていましたが、コラムを書くにあたり調査してみたら、最近の文書ではあまり使われてない?みたいです。
まとめと次回:NN順方向の実装
今回は、活性化関数の主なものについて、単純パーセプトロンで使われていたステップ関数と比較しながらシグモイドと最近の主流Reluについて紹介しました。
次回は、これらをPythonで実装してみようと思います。
【仕組み解説】全結合層をゼロから実装しよう:全結合層の順方向だけ実装してみる。(NN #8)
これまでの理論に基づき、順伝播(Forward)をゼロから実装します。入力から予測値を導くNNの骨格を作り上げます。
11 記事
ゼロから作る全結合層
ゼロから作る全結合層シリーズでは、初心者でも理解しやすいように、 「パーセプトロンの仕組み」から「全結合層の実装」までを...
ここまで読んでいただきありがとうございます。
では、次の記事で。 lumenHero



