前回は、nnモデルを作り、学習の1ステップを行ってみたと思います。

【仕組み解説】逆伝播と更新のサイクルを実装:「心臓部」の動きを理解(NN #10)
逆伝播とパラメータ更新のサイクルをゼロから実装。NNの「心臓部」を動かし、学習の仕組みを完成させます。
今回は、前回実装したモデルを学習させて、XOR問題が解けるようになろうと思います。
 11 記事
11 記事
ゼロから作る全結合層
ゼロから作る全結合層シリーズでは、初心者でも理解しやすいように、 「パーセプトロンの仕組み」から「全結合層の実装」までを...
この記事シリーズでは、ディープラーニングに入るまでの道筋をその根本的な設計思想からディープラーニングの肝であり、基礎の最小単位である全結合層について、ゼロから作って理解していきます。
入力データの用意
XOR問題を解いてみたいので、XORの入力と出力を用意します。
[0,0] \(\to\) 0
[0,1] \(\to\) 1
[1,0] \(\to\) 1
[1,1] \(\to\) 0
データの準備
テンソル(行列)にしたいので、ちょっこっと整形してます。
import numpy as np
# 0. データの準備
# 入力(X): 4件のデータ, 2つの特徴量
X_xor = [[0.0,0.0],[0.0,1.0],[1.0,0.0],[1.0,1.0]]
T_xor = [[0.0], [1.0], [1.0], [0.0]]
X_xor_array = np.array(X_xor)
T_xor_array = np.array(T_xor)
X = torch.from_numpy(X_xor_array).float()
T = torch.from_numpy(T_xor_array).float()
print(f"X shape: {X.shape}, dtype: {X.dtype}") # dtype float32
print(f"T shape: {T.shape}, dtype: {T.dtype}")
print(X.shape)
print(T.shape)学習ループの実装 (EPOCH)
学習では、1回データを学習させることをエポックといいます。
また、エポックを回すというような表現もされます。
なぜ「エポック(時代)」なんて大層な言葉を使うの?
「Epoch」は元々、歴史用語で「新時代」や「画期的な区切り」を意味する言葉です。 AIの世界では、「用意された問題集(データセット)を、全部まるっと1周やり終えること」を1エポックと呼びます。
今回実装するコードでは、そもそものデータ量が少ないので、1ステップで全データ通しています。
なので、今回に限ると 1ステップ = 1エポックです。
このように全データを一回で学習に通すことを バッチ学習といいます。
データ量が多くなり、データを分割しないと学習できない場合、(例:今回は全体の5%を学習に通し、それを20回繰り返して全部を通す)ような方法をミニバッチ学習といいます。前々回くらいに触れたバッチサイズはここに関係があります。
- (バッチ学習): データが4つ(XOR)しかないので、1回計算するだけで「全データ」を見終わります。 だから、1ステップ = 1エポック です。
- (ミニバッチ学習): もし、データが「10,000問」あったとき、 一気に計算するとメモリがパンクしてしまいます。 そこで、例えば「100問ずつ(ミニバッチ)」小分けにして解いていきます。
- 1ステップ: 100問だけ解いて、少し賢くなる。
- 1エポック: 100回ステップを繰り返して、ついに10,000問すべてを解き終わる。
つまり、
「問題集を1ページ進めるのがステップ」、
「問題集を最後までやりきって1周するのがエポック」。
「1周したぞ!」という大きな区切りだから、歴史のような「エポック」という言葉を使う…とイメージなので、ステップではなく、エポックという風に呼ばれます。
学習ループのコード
実際に学習を回してみます。前回の実装で、学習1エポック分の実装は完了しているので、前回のコードをまるまるループに入れるだけです。
epoch = 10000
print("--- 学習サイクル開始 ---")
for e in range(epoch):
# === STEP 1: 順伝播 (知る) ===
out = X
for layer in layers:
out = layer.forward(out)
y_pred = out # AIの予測値
# === ロス計算 ===
loss = loss_layer.forward(y_pred, T)
# === STEP 2: 考える (Backward) ===
# 一番後ろのLoss層からスタート
# dout(間違った量) = t-y
dout = loss_layer.backward()
# レイヤーを逆順にして誤差を伝えていく
for layer in reversed(layers):
dout = layer.backward(dout)
# === STEP 3: 更新 (Update) ===
# パラメータを持っている層(Affine)だけ更新
# W = W - lr * dW
layers[0].W -= learning_rate * layers[0].dW
layers[0].b -= learning_rate * layers[0].db
layers[2].W -= learning_rate * layers[2].dW
layers[2].b -= learning_rate * layers[2].db
# --- 確認:本当によくなった? ---
if e % 100 == 0:
print(f"Epoch {e}: Loss {loss.item():.4f}")
# 学習の成果(予測値)途中経過
if e % 5000 == 0:
print(f" 予測値:\n{y_pred.detach().numpy()}") # detachで計算グラフから切り離して表示
# ループ終了後、最終結果を表示 ===
print("--- 学習終了 ---")
print(f"最終Loss: {loss.item():.4f}")
print("最終予測結果:")
print(y_pred)【仕組み解説】逆伝播と更新のサイクルを実装:「心臓部」の動きを理解(NN #10)
逆伝播とパラメータ更新のサイクルをゼロから実装。NNの「心臓部」を動かし、学習の仕組みを完成させます。
学習結果
1. うまく行ったとき
学習がうまく行くと、以下のような結果が最終的に出力されるはずです。
うまく行ったときの学習結果
--- 学習終了 ---
最終Loss: 0.0000
最終予測結果:
tensor([[3.1134e-06],
[1.0000e+00],
[1.0000e+00],
[7.0001e-07]])有効数字表記なので分かりづらいかもしれませんが、
[3.1134e-06] \(\to \) ほぼ0
[1.0000e+00]\(\to \) 1
[1.0000e+00]\(\to \) 1
[7.0001e-07]\(\to \) ほぼ0
とxor問題を解けたことが確認できます!
2. ローカルミニマムに捕まったとき
毎回うまく行けばいいのですが、
何回か重みの初期化と学習を回してみると以下のような Lossが 0.25とか 0.33のままになって、それ以上学習できなくなってしまうことがあります。
ローカルミニマムに捕まったときの結果
...
Epoch 9300: Loss 0.2500
Epoch 9400: Loss 0.2500
Epoch 9500: Loss 0.2500
Epoch 9600: Loss 0.2500
Epoch 9700: Loss 0.2500
Epoch 9800: Loss 0.2500
Epoch 9900: Loss 0.2500
--- 学習終了 ---
最終Loss: 0.2500
最終予測結果:
tensor([[5.0000e-01],
[1.0000e+00],
[5.0000e-01],
[8.0466e-07]])Lossがずっと 0.25になって学習できていません。
結果を見ても、正答を答えられていません。
ここで注目してほしいのが 1つ目と3つ目の 0.5 (5.000e-1 )という値です。
これは、0か1と答えるべきなのに、どちらに答えたらいいかわからないからとりあえず、Lossが小さくなるためには真ん中を答えてしまえばいい!と学習してしまった結果と言えます。
これは、勾配降下法で一番最適な底ではなく、途中にある最適でないポケットのようなところにハマってそれ以上学習できなくなる問題。
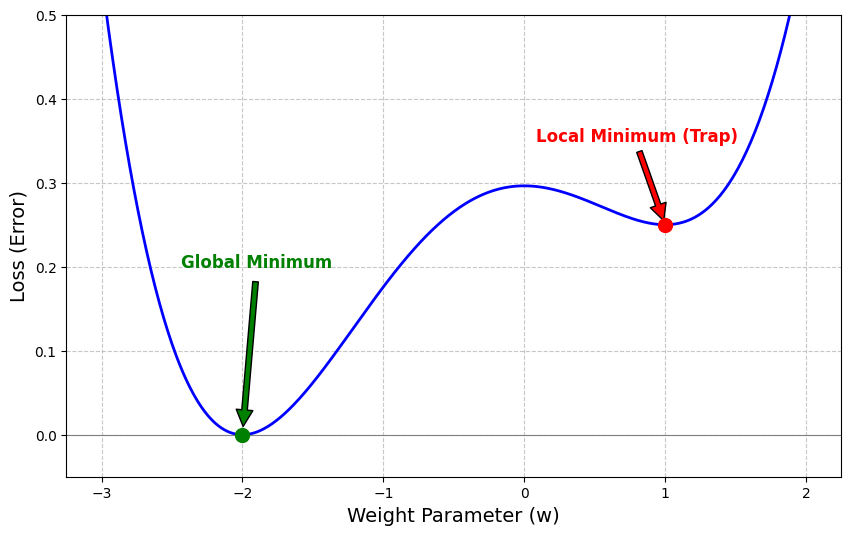
ローカルミニマム(局所的最小値)
端的に言うと「近くの範囲では一番低い(最小)けれど、全体で見るともっと低い(最小)場所があるかもしれない地点」に捕まってしまったことを意味しています。
ローカルミニマムの原因は?
今回の犯人は、おそらく「死んだReLU (Dying ReLU)」現象と考えられます。
実装したReLU関数を思い出してください。 「0以下なら通さない(0にする)」というルールでしたよね。
もし、初期重みの運が悪くて、あるニューロンへの入力がすべてのデータに対して「マイナス」になってしまったら?
- そのニューロンの出力は常に
0になる。 - 逆伝播(Backward)しても、傾きが
0になってしまう(スイッチが切れているから)。 - 重みが更新されない。
こうなると、そのニューロンは学習期間中ずっと「死んだまま」になり、復活しません。 隠れ層のニューロンが少ない(今回は4つ)場合、運悪く全員が死んでしまったり、うまく機能しない組み合わせになると、そこから抜け出せなくなってしまうんです。
対策は?
対策はいくつかありますが、主に以下の3つの方法で対処します。
- ニューロンの数を増やす(数で殴る作戦)
- 重みの初期化を工夫する(Heの初期化)
- ガチャを回し直す(再実行)
ニューロン数が少なかったことが原因なので、1つ目のニューロン数を増やせば、今回なら10くらいに増やせば、ほぼ確実に解決できます。
まとめ
今シリーズでは、全結合層をゼロから実装しようということで、ゼロから全結合層を作ってみました。
学習の仕組みやなぜ多層化しないといけないのか、なぜ活性化関数が必要なのか理解できたと思います。
11 記事
ゼロから作る全結合層
ゼロから作る全結合層シリーズでは、初心者でも理解しやすいように、 「パーセプトロンの仕組み」から「全結合層の実装」までを...
このシリーズは一旦ここで締めとしますが、
今後は、ここから発展して、CNN(畳み込みニューラルネットワーク)やRNN(リカレントニューラルネットワーク)、どうやったらローカルミニマムなどの学習の障害をうまく超えられるか、を理解しやすく紹介していこうと思っています。
このカテゴリ、深層学習の基礎知識にて、適宜記事をあげていこうと思うので、もし興味があれば、見ていってくれると幸いです。
ここまで読んでいただきありがとうございます。
では、次の記事で。 lumenHero