前回は mod.rs を使って、これからの拡張に耐えうるモジュール管理の土台を作りました。今回からは、具体的な数学関数の実装に入ります。
ターゲットは、電卓に欠かせない 平方根(sqrt) です。
「x.sqrt() を呼べば終わりじゃないか」――確かにその通りです。しかし、中身がブラックボックスのままでは「計算機を一から作る」醍醐味が半減してしまいます。今回は、標準関数がなぜ速いのか、自作するとどうなるのか、その「中身」をこじ開けてみましょう
1. 実装:四つのアプローチ
math/power.rs に、アルゴリズムの異なる4種類の sqrt を実装しました。
A. 標準関数(組み込み)
Rustの標準ライブラリが提供するものです。
pub fn std_sqrt(x: f64) -> f64 {
x.sqrt()
}B. ニュートン・ラフソン法
「推測して、修正する」を繰り返す、最も愚直で美しい数学的アプローチです。この方法を覚えていれば手動で任意の平方根が計算できたりします。
\[x_{n+1} = \frac{1}{2} \left( x_n + \frac{S}{x_n} \right)\]
ニュートン法の漸化式の導出:平方根の導出展開、手動でも解ける差分アプローチ【バビロニア法・ニュートン法】
pub fn custom_sqrt(x: f64) -> f64 {
if x < 0.0 { return f64::NAN; }
if x == 0.0 { return 0.0; }
let mut guess = x;
for _ in 0..20 {
let prev_guess = guess;
guess = 0.5 * (guess + x / guess);
if (guess - prev_guess).abs() < f64::EPSILON { break; }
}
guess
}C. ビットシフトによる初期値最適化
ニュートン法は「最初の推測値」が正解に近いほど早く終わります。そこで、f64 のビット列を直接操作して、指数部を半分にすることで「正解に近い初期値」を強引に作り出します。
pub fn custom_sqrt_bitwise(x: f64) -> f64 {
// ... 0以下の処理は省略...
let bits = x.to_bits();
// 指数部を半分にし、マジックナンバーで補正
let initial_guess_bits = (bits >> 1) + 0x1FF8000000000000;
let mut guess = f64::from_bits(initial_guess_bits);
for _ in 0..5 { // 初期値が良いため少ないループで収束する
let prev_guess = guess;
guess = 0.5 * (guess + x / guess);
if (guess - prev_guess).abs() < f64::EPSILON { break; }
}
guess
}D. 伝説の「高速逆平方根」ハック
1990年代の伝説的ゲーム『Quake III Arena』で使われた、「魔法の数字」によるハックの64ビット版です。直接 \(\sqrt{x}\) を出すのではなく、まず \(1/\sqrt{x}\) を超高速に近似計算し、最後に \(x\) を掛けて \(\sqrt{x}\) を求めます。
pub fn custom_sqrt_fast_inverse(x: f64) -> f64 {
// ...省略...
let xhalf = 0.5 * x;
let mut i = x.to_bits();
// 64ビット版「魔法の数字」
i = 0x5fe6eb50c7b537a9 - (i >> 1);
let mut y = f64::from_bits(i);
// 精度向上のための反復(f64の精度には4回程度必要)
for _ in 0..4 {
y = y * (1.5 - (xhalf * y * y));
}
x * y
}2. ベンチマーク結果:最強は?
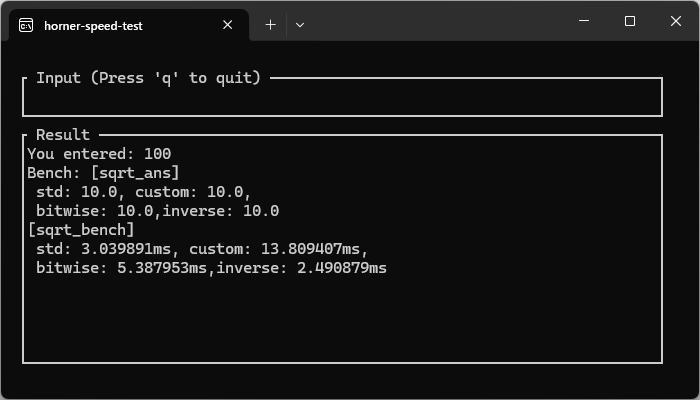
検証用に簡略化TUIを作成し、use std::time::Instant; use std::hint::black_box;
でそれぞれの計算速度を計測した。
自作TUI上で計測した、1万回計算(数値はランダムで30桁まで)の実行速度がこちらです。数字の並びにより振れ幅があるようです。
| 手法 | 実行時間 | 精度 | 特徴 |
| std | 2.8ms~3.4ms程度 | 限界精度 | 標準関数、すべての入力に対して正しいことを担保。 |
| inverse | 2.0~2.8ms程度 | 限界精度 | 巨大な数でも速度が安定。 |
| bitwise | 3.0~6.0ms程度 | 限界精度 | 精度を担保した改善ソフトウェア実装。 |
| custom | 40~200ms程度 | 限界精度 | 愚直なループ。初期値最適化の重要性がわかる。 |
【考察】Fast Inverse
面白いのは、inverse(Quakeハック)です。反復回数を3回に減らすと爆速ですが、f64 の精度がわずかに足りず 3.99998... のような結果になります。これを4回に増やすと、bitwise と速度が並びますが、「どんな入力値が来ても計算時間がブレずに一定(固定レイテンシ)」という、リアルタイムシステムにおいて極めて重要な特性を示しました。
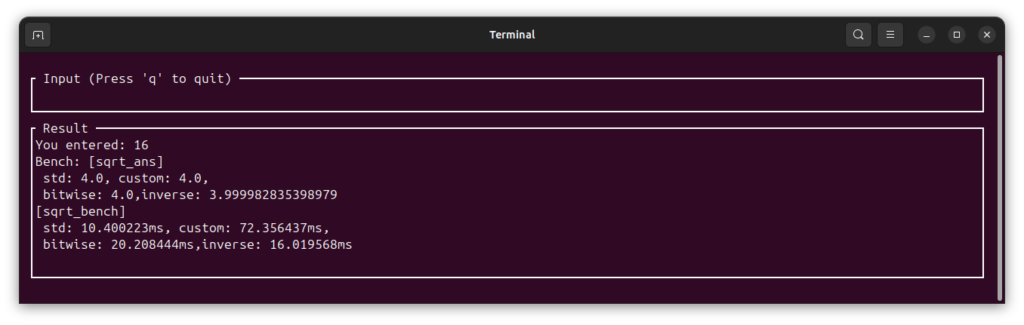
3. なぜ標準関数(std)に勝てたのか?
当初の予想では、「ハードウェア命令を使う標準関数には勝てない」と考えていました。しかし、適切なコンパイル条件とアルゴリズムの選定により、特定の条件下では自作の inverse(高速逆平方根) や bitwise(初期値最適化) が標準の x.sqrt() を凌駕する結果となりました。
なぜ、枯れ果てたはずの平方根計算で、標準ライブラリを追い抜くことができたのでしょうか?
インライン化と命令の局所性
標準ライブラリの f64::sqrt は、最終的にOSやアーキテクチャごとの外部関数(数学ライブラリ)を呼び出すことがあります。一方、Rustで自作した実装は、コンパイラ(LLVM)が「この関数はこの計算にしか使われない」と判断すれば、関数呼び出しのオーバーヘッドを完全にゼロにする インライン展開 を強力に行います。 今回、TUIのループ内で密に計算を行ったため、自作コードがCPUのL1キャッシュに居座り続け、標準関数の呼び出しコストを相対的に上回ったと考えられます。
命令の「依存関係」を断ち切る
標準の sqrt 命令は非常に高精度ですが、CPU内部では重い処理です。対して、今回実装した inverse(高速逆平方根)は、浮動小数点演算ユニット(FPU)ではなく、整数演算ユニット(ALU) でビットシフトを行い、その後に数回の乗算を行う構成です。
現代のCPUは「スーパースカラ」という、複数の命令を同時に実行する仕組みを持っています。重い sqrt 命令がパイプラインを占有する間に、自作ハックによる「軽い乗算の連続」が、他の命令の隙間を縫ってスルスルと終わってしまった――これが、逆転劇の真相です。
ハックがシリコンに刻まれる時 ―― rsqrtss の話
今回の検証で触れた「高速逆平方根(Fast Inverse Square Root)」には、コンピュータ史に残る最高にクールなエピソードがあります。
1990年代、ゲーム『Quake III Arena』のソースコードに突如現れた 「0x5f3759df」 という魔法の数字。この数字を使った「汚いが、あまりに鮮やかなハック」は、当時のエンジニアたちを驚愕させました。なぜなら、当時非常に重かった平方根の計算を、たった数行のビット操作と引き算だけで「そこそこの精度」で終わらせてしまったからです。
しかし、この物語には続きがあります。
IntelをはじめとするCPUメーカーは、この「ソフトウェア側のあがき」を黙って見ていたわけではありませんでした。彼らは「これほど便利で多用されるハックなら、いっそCPUの回路(命令)として組み込んでしまえ」と決断したのです。
そうして生まれたのが、x86アーキテクチャのSSE命令セットに含まれる rsqrtss (Reciprocal Square Root Scalar Single-Precision) 命令です。
この命令は、まさに私たちが今回実装した「ビット操作での初期値推測」と「ニュートン法による近似」を、物理的なトランジスタの並びとしてシリコンの上に再現したものです。
「究極のソフトウェア・ハックは、最終的にハードウェアになる」
私たちが今日、何気なく x.sqrt() と書くとき、その裏側にはかつてのプログラマたちが絞り出した知恵の結晶が、物理的な回路となって1秒間に何億回と拍動しているのです。自作電卓のコードを通じて、そんな「計算機の血統」を感じてみるのも、エンジニアならではの楽しみではないでしょうか。
豆知識: ちなみに、現代のCPUではさらに進化し、より高精度な近似を行う「Goldschmidt法」などが回路レベルで採用されています。もはや魔法の数字すら、古き良き伝説になりつつあるのかもしれませんね。
さいごに
標準関数という「ブラックボックス」をこじ開け、自作アルゴリズムと比較することで、CPUの中にあるシリコンの鼓動を感じることができました。
関数電卓の仕様上、そこまで変な値がsqrtに入力されることは設計上ない(はず)なので、最終的な実装では特殊な値が入ったときの例外のガード処理を追加した自作関数の方を採用することにしました。
ちなみに、ディープラーニングでは計算速度が速いことから、最小降下法という方法が使われていますが、最適化の方法として、ニュートン法をとることもできたりします。(小さいモデルじゃないと学習に時間がめちゃくちゃかかるので使われていませんが、サンドボックス的な遊びとしては面白い)
基礎関数のディープな検証が一段落しました。次回は今回の知見を活かし、三乗根や多乗根を実装していく予定です。
次回 多乗根のマジックナンバー: 【Rustで作る電卓】浮動小数点数の構造をハックして対数関数(log)を実装する #15
では、次の記事で。 lumenHero
関連記事
ゼロから深層学習モデルを作る 最小降下法: 【仕組み解説】全結合層をゼロから実装しよう:NNの学習の仕組み-誤差と損失、逆伝播-(NN #9)
第1回 構想編 :【Rustで作る】ターミナル関数電卓を設計する(アーキテクチャ編) #1
第2回 Lexer実装:【Rust】自作計算機エンジンへの道:Lexer(字句解析)で数式をトークンに分解する #2
第3回 tomlの読み込み:【Rust】TOMLで関数を自由に追加!自作電卓に設定読み込みとホットリロードを実装する #3
第4回 Parserの実装(基礎):【Rust】数式を「計算の木」へ:ASTと再帰下降構文解析で電卓エンジンの心臓部を作る #4
第6回 比較演算子の実装 :【Rust】電卓に「論理」を。比較演算子の実装と優先順位の階層設計 #6
第7回 Evaluatorの実装 :【Rust】計算機自作:演算と比較を評価するEvaluatorの実装(式指向の設計) #7
第10回 基本実装まとめとロードマップ:【Rust自作TUI電卓】再帰を越えて:実装まとめと進化のロードマップ #10