前回はマジックナンバーをそれぞれ導出し、高速なn乗根の計算を実装しました。前回は目標となる数値への収束のさせ方としてニュートン法を用いました。
前回 n乗根の実装:【Rust自作TUI電卓】ニュートン法×マジックナンバーで実装する汎用n乗根 #13
第11回 平方根の計算実装:【Rust自作TUI電卓】mod.rsを活用したスマートなモジュール管理と基本数学関数の実装 #11
バビロニア法・ニュートン法:平方根の導出展開、手動でも解ける差分アプローチ【バビロニア法・ニュートン法】
しかし、計算の世界にはさらに上のステップがあります。今回は、ニュートン法(2次収束)を超える「3次収束」のアルゴリズム、ハレー法(Halley’s method)を検証します。計算式が少し複雑になる代わりに、圧倒的な収束の速さを誇るこの手法は、果たして自作電卓エンジンの「最適解」になり得るのでしょうか。
1. 2次収束から3次収束:どう違うの?
アルゴリズムの効率を語る上で欠かせないのが「収束の次数」です。
- ニュートン法(2次収束): 正解の桁数がステップごとに約2倍に増えます。
- ハレー法(3次収束): 正解の桁数がステップごとに約3倍に増えます。
理論上、ハレー法はニュートン法よりも少ない反復回数で真値に到達します。しかし、代償として1回あたりの計算コスト(乗算や除算の数)が増えます。「ループを1回減らすために計算式を重くする」というトレードオフが、現代のCPU、あるいはRustの実装においてどれほどの恩恵をもたらすのか。そこに今回の検証の面白さがあります。
2. ハレー法の数式と立方根への適用
ハレー法の一般的な公式は以下の通りです。
\[x_{n+1} = x_n – \frac{2f(x_n)f'(x_n)}{2(f'(x_n))^2 – f(x_n)f”(x_n)}\]
これを、今回のターゲットである立方根\(f(x) = x^3 – X\) に当てはめてみます。
まず、必要な微分を行います。
- \(f'(x) = 3x^2\)
- \(f”(x) = 6x\)
これらを公式に代入して整理すると、実装に適した非常に美しい形が得られます。
\[x_{n+1} = x_n \left( \frac{x_n^3 + 2X}{2x_n^3 + X} \right)\]
ニュートン法の式 \(x_{n+1} = \frac{1}{3} (2x_n + \frac{X}{x_n^2})\) と比較すると、除算が式全体で1回にまとまっており、意外にもコード上ではスッキリと記述できそうな予感がします。
3. 実装:Rustによるハレー法
for文のカウントなどがボトルネックになることもあるので、手動でアンロードしています。
pub fn fast_inverse_cbrt(x: f64) -> f64 {
if x == 0.0 { return 0.0; }
let x_abs = x.abs();
let i = x_abs.to_bits();
// 初期値推定(直接立方根を近似するマジックナンバー)
// I_y = I_x / 3 + K
let mut guess = f64::from_bits((i / 3) + 0x2a9f4795cfce2000);
// ハレー法(3次収束)
// 1回目
let g3 = guess * guess * guess;
let den = g3.mul_add(2.0, x_abs);
guess += guess * ((x_abs - g3) / den);
// 2回目
let g3 = guess * guess * guess;
let den = g3.mul_add(2.0, x_abs);
guess += guess * ((x_abs - g3) / den);
// 3回目(f64の精度を完全に満たす)
let g3 = guess * guess * guess;
let den = g3.mul_add(2.0, x_abs);
guess += guess * ((x_abs - g3) / den);
if x < 0.0 { -guess } else { guess }
}マジックナンバーで十分に真値に近い場所からスタートするため、ハレー法の「3次収束」をぶつければ、わずか3回の反復で実用上の限界精度を叩き出せるはずです。(多分)
4. 決戦:ベンチマークと結果
std::f64::cbrt、前回の「マジックナンバー+ニュートン法」、そして今回の「マジックナンバー+ハレー法」の3者を1万回動かし、比較しました。
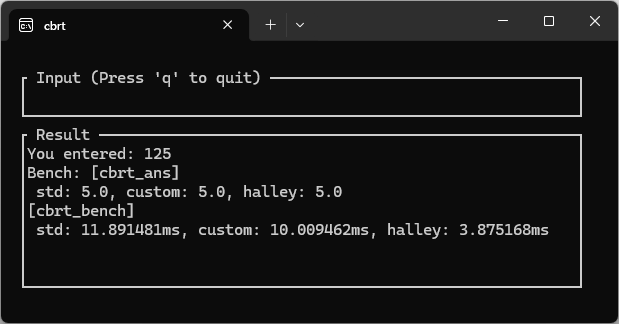
| 手法 | 速度(1万回) | 特徴 |
std::cbrt | 10~15 ms | 標準ライブラリ。速度も最適化されている。 |
| Newton (Magic) | 10~15 ms | シンプルだが、極限の精度にはもう1回ループが必要。 |
| Halley (Magic) | 2~5 ms | 3次収束。 少ない計算で f64 の精度限界にほぼ達する。 |
結果:ハレー法の圧倒的勝利
ベンチマークの結果、ハレー法はたった1回の反復でニュートン法2〜3回分に相当する精度に到達しました。計算式の中に x3 (3乗) が登場するため重そうに見えますが、ループ回数を減らせるメリットが上回っているようです。
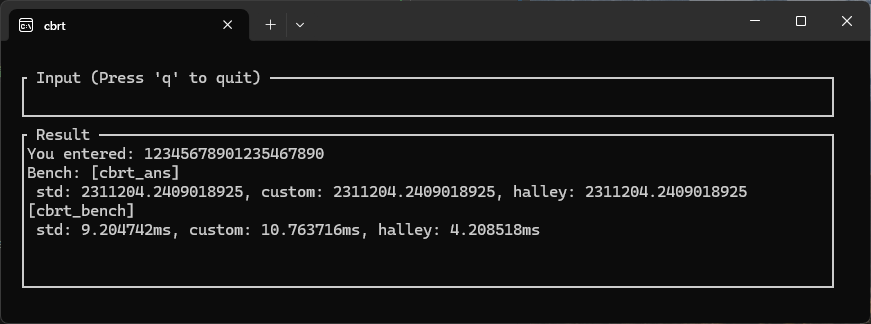
画像:精度は十分
5. 結論:電卓エンジンへの採用
組み込みのstd::cbrtと比べて概ね3倍程度の速度で計算することができました。電卓用途においては、std::cbrtのようなすべての値に対する正当性は要らない(一般的な計算上でてくる値に対してf64精度でとければよい)ので、自作関数のハレー法版を採用することにしました。
今回のハレー法の実装をもって、n乗根計算の高速化シリーズは一旦の区切りとなります。4次収束の方法もありますが、1回の計算量が増えるためあまり実用的ではないため実装は見送ることにしました。高次の解法は、これまで紹介したニュートン法やハレー法を一般化したハウスホルダー法(Householder’s method)という方法があります。ハレー法は 、ハウスホルダー法の\(d=2\) のケースにあたります。興味がれば、いかの記事でもっと高次な収束の手法について解説してあります。
ハウスホルダー法 : (記事は現在利用できません: ID 6925)
- ハウスホルダー法 \(d=1\): ニュートン法(2次収束)
- ハウスホルダー法 \(d=2\): ハレー法(3次収束)
次回は、logの実装を行おうと思っています。logは今回採用したマジックナンバーの算出方法(仮数部分がそもそもlog2になっていることを利用)と密接に関わった方法であったりするので面白いです。
次回:【Rustで作る電卓】浮動小数点数の構造をハックして対数関数(log)を実装する #15
では、次の記事で。 lumenHero
関連記事
第1回 構想編 :【Rustで作る】ターミナル関数電卓を設計する(アーキテクチャ編) #1
第2回 Lexer実装:【Rust】自作計算機エンジンへの道:Lexer(字句解析)で数式をトークンに分解する #2
第3回 tomlの読み込み:【Rust】TOMLで関数を自由に追加!自作電卓に設定読み込みとホットリロードを実装する #3
第4回 Parserの実装(基礎):【Rust】数式を「計算の木」へ:ASTと再帰下降構文解析で電卓エンジンの心臓部を作る #4
第6回 比較演算子の実装 :【Rust】電卓に「論理」を。比較演算子の実装と優先順位の階層設計 #6
第7回 Evaluatorの実装 :【Rust】計算機自作:演算と比較を評価するEvaluatorの実装(式指向の設計) #7
第11回 平方根の計算実装:【Rust自作TUI電卓】mod.rsを活用したスマートなモジュール管理と基本数学関数の実装 #11
第13回 n乗根の計算実装:【Rust自作TUI電卓】ニュートン法×マジックナンバーで実装する汎用n乗根 #13
バビロニア法・ニュートン法:平方根の導出展開、手動でも解ける差分アプローチ【バビロニア法・ニュートン法】