ヒープソートの「ヒープ」ってなに?
これまでの記事で、 \(O[n^2]\) の単純ソートや、\(O[n \log n]\) の高速なマージソート、クイックソートなどを学んできました。
このシリーズの記事一覧:https://tukumolog.com/series/sort-algorithm-introduction
高速なソートには、もう一つ有名なアルゴリズム「ヒープソート」があります。
しかし、この名前を聞いて「”ヒープ”って一体何?」と疑問に思う方も多いでしょう。
プログラミングにおける「ヒープ(Heap)」は、単なる「山」(直訳は”山”とか”積み重ね”)という意味ではありません。これは、特定のルールに基づいて要素が並べられた、非常に効率的なデータ構造(データの入れ物)の名前です。
ヒープソートを理解するには、まずこの「ヒープ」というデータ構造の正体を知る必要があります。
この記事では、ヒープソートの鍵となる「ヒープ」の仕組みについて、分かりやすく解説していきます。
1. ヒープとは?(一言でいうと)
ヒープとは、一言でいえば「常に最大値(または最小値)を効率よく取り出せるデータ構造」です。
見た目は「木構造(ツリー)」の一種ですが、非常に厳密な2つのルールによって成り立っています。
病院のトリアージ(優先度)のイメージ
ヒープの最も分かりやすい例は、病院の救急外来で行われる「トリアージ(優先度判定)」です。
- 患者(データ)は次々と運ばれてきます。
- しかし、処理(治療)される順番は、到着順(単純なキュー)ではありません。
- 「緊急度(優先度)」が最も高い患者から先に治療室に呼ばれます。
ヒープは、このような「優先度付きキュー(Priority Queue)」を実現するための、最も代表的なデータ構造なのです。「後から追加されたデータでも、優先度(値)が最大なら、すぐ取り出せる」のが特徴です。
2. ヒープが守るべき「2つの厳格なルール」
ヒープが「ヒープ」であるためには、以下の2つのルールを同時に満たしている必要があります。
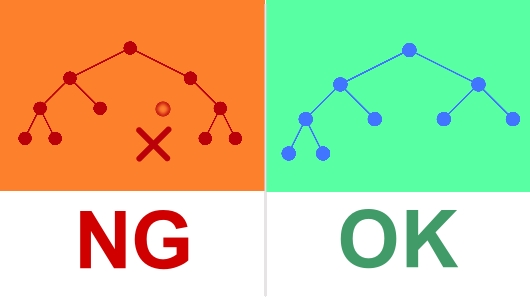
ルール1:形状のルール \(\to\) 「完全二分木」であること
これは「木の形」に関するルールです。
「完全二分木(Complete Binary Tree)」とは、簡単に言えば「左上から順に、隙間なく要素が詰まっている木」のことです。
- OK(完全二分木): 途中の段がスカスカだったり、右側だけ先に伸びていることはありません。
- NG: 最後の段以外で要素が欠けている。
この「隙間なく詰まっている」という性質が、後で説明する「配列での実装」に非常に重要になります。(一番下は埋まってなくても問題ありません)
ルール2:親子のルール \(\to\) 「ヒープ条件」を満たすこと
これは「要素の値」に関するルールです。
親の要素は、その2つの子の要素よりも常に大きい(または小さい)
このルールによって、2種類のヒープが存在します。
① 最大ヒープ (Max Heap)
親 > 子
親は子より常に大きい(または等しい)。
- 結果: 木の一番上にある「根(ルート)」には、必ずデータ全体の「最大値」が来ます。
- (ヒープソートで主に使われるのはこちらです)
② 最小ヒープ (Min Heap)
親 < 子
親は子より常に小さい(または等しい)。
- 結果: 根(ルート)には、必ずデータ全体の「最小値」が来ます。
- (優先度付きキューで「緊急度が一番高い(値が小さい)」ものを取り出す場合に使われます)
重要: ヒープは「親子の間」の大小関係しか保証しません。「兄弟の間(例:22と15)」や「叔父と甥(例:11と15)」の大小関係は問わないことに注意してください。
3. 最も重要:ヒープは「配列」で表現できる
ヒープは見た目こそ「木」ですが、コンピュータで実装する際は「配列」を使うのが一般的です。
「なぜ?」と思うかもしれませんが、その秘密は先ほどの「ルール1:完全二分木」にあります。
要素が左上から隙間なく詰まっているので、木の「レベル(段)」ごとに左から順に番号を振っていき、その番号をそのまま「配列のインデックス」に対応させることができます。
そして、この配列を使えば、あるノード(インデックス i)の「親」や「子」がどこにあるかを、簡単な計算で一発で特定できます。
あるノード(インデックス
i)に対して:
- 親のインデックス:
floor( (i - 1) / 2 )- 左の子のインデックス:
2 * i + 1- 右の子のインデックス:
2 * i + 2
例えば、インデックス 4(値: 19)のノードは…
- 親:
floor( (4 - 1) / 2 )=floor(1.5)= インデックス1(値: 36) - 左の子:
2 * 4 + 1= インデックス9(値: 17)
この「見た目は木、実体は配列」という性質こそが、ヒープおよびヒープソートの効率の良さの核となります。
4. ヒープの基本操作(ヒープソートの予習)
ヒープソートでは、このヒープ構造を維持・利用するために2つの基本操作を使います。
操作1:データの挿入(ヒープの構築)
ヒープに新しいデータを追加するときは、「2つのルール」を壊さないように挿入します。
- まず「形状のルール」を守るため、データを木の一番最後(=配列の末尾)に追加します。
- しかし、これだけでは「親子のルール」を破る可能性があります(例:親が30で、子が100)。
- もしルール違反なら、親と子を交換します。
- 交換した後、さらにその上の親とも比較し、ルール違反なら交換…を、根(ルート)に到達するか、ルールが満たされるまで繰り返します。
この「下から上へ」と秩序を回復していく操作を「ヒープ化 (heapify-up)」と呼びます。
操作2:最大値(根)の削除(ヒープソートの核)
これがヒープソートのアルゴリズムそのものです。
- ヒープ(最大ヒープ)の根(ルート)は、必ず「最大値」です(ルール2より)。
- この根(最大値)を引っこ抜きます。(これでソート済み配列の末尾が1つ確定します)
- しかし、根がなくなると木に穴が空いてしまい、「形状のルール」が崩れます。
- そこで、とりあえず木の一番最後の要素(=配列の末尾)を、根の位置に持ってきます。
- 当然、この要素は最大値ではないので、「親子のルール」が(ほぼ確実に)壊れます。
- 新しい根と、その「2つの子」を比較し、一番大きい子と交換します。
- 交換した後、さらにその下の子と比較し、交換…を、葉(末端)に到達するか、ルールが満たされるまで繰り返します。
この「上から下へ」と秩序を回復していく操作を「ヒープ化 (heapify-down)」と呼びます。
まとめ(ヒープソートへ)
- ヒープとは、「最大値(or 最小値)がすぐに取り出せる」データ構造です。
- 「① 完全二分木(隙間なし)」と「② 親>子(or 親<子)」の2つのルールで成り立っています。
- 見た目は木ですが、実装は「配列」で行うのが一般的です。
- ヒープソートは、このヒープ構造の「最大値(根)の削除」操作を繰り返し利用するソートです。
ヒープの基本が分かったところで、次はいよいよ、この仕組みを使ってどのように $O(n \log n)$ の高速ソートを実現するのか、「ヒープソート」の具体的なアルゴリズムを見ていきましょう。
ヒープソートの仕組みを徹底解説!アニメーションで学ぶ「砂山(heap)」ソート【ソートアルゴリズム入門】#11
マージソート、クイックソートに続く「第3の \(O[N \log N]\) ソート」 こんにちは!これまで、 \(O[n^2]\) の壁を超える高速なソートアルゴリズムとして、「分割統治法」に基づくマージソートとクイック […]
ここまで読んでいただきありがとうございます。
では、次の記事で。 lumenHero