特定条件でめっちゃ早い(\(O[n]\))カウンティングソート
前回の記事で「比較するのをやめる」ソートについて、軽く触れてみましたが、今回紹介する”カウンティングソート”は、データのとりうる値が決まっている場合に、はじめからそれらを入れる容器を決めて置き、データを順に見ていき、該当する容器に割り振る。最後に、割り振った容器(初めから順序がわかっている)をつなげる。という手順でソートします。

O[n log(n)] の壁を超える!「比較しないソート」【ソートアルゴリズム入門】#12
比較しないソートとは?比較ソートの計算量O[n log(n)]を超える別のアプローチについてその導入を紹介します。
カウンティングソート実行アニメーション
今回の記事では、テストの点数(0から100点)をカウンティングソートでソートする例をもとに仕組みについて解説していきたいと思います。
1. カウンティングソート(Counting Sort・計数ソート)とは?
カウンティングソートは、その名の通り「カウント(計数)」を利用するソートアルゴリズムです。比較ソートのように「要素同士を比べる」のではなく、「どの値が何個あるか」を数え上げ、その集計結果を基に並び替えます。
この手法が使えるのは、前回の記事の最後で触れたように、データが「特定の性質」を持っている場合に限られます。
- 条件1: データが整数(または整数にマッピングできる)であること。
- 条件2: データの最小値と最大値(とりうる値の範囲)がわかっていること。
- 条件3: その「範囲」が、コンピュータのメモリで扱える程度に現実的な大きさであること。
今回の「0点から100点までのテスト結果」という例は、これらすべての条件を満たす完璧な例です。このほかにも生年月日などのソートでも有用です。1万歳のエルフなどは現実にはいない?ので。
\(O[n+k]\) という圧倒的スピード
カウンティングソートの計算量は (\(O[n+k]\)) と表されます。 ここで、
- \(n\) は、ソートしたいデータの総数(例:生徒1000人)
- \(k\) は、データのとりうる値の範囲(例:0点〜100点なら (k = 101))
もし1000人の生徒の点数(0〜100点)をソートする場合、
- 比較ソート(マージソートなど): \(O[n \log n]\) なので、約 \(1000 \times 10 = 10000\) 回の比較が必要です。
- カウンティングソート: (\(O[n+k]\))なので、約 (1000 + 101 = 1101) 回の処理で済みます。
\(k\)(データの範囲)が \(n\)(データ数)に比べて極端に大きくなければ、ほぼ \(O[n]\) に近い、驚異的な速度を達成できます。
2. カウンティングソートで「テストの点数」を並び替えたら?
では、実際に [ 75, 50, 80, 50, 95, 75 ] という6人分のテスト結果(0〜100点)をソートする手順を見ていきましょう。
ステップ1:準備 (バケツの用意)
まず、データの範囲である「0点」から「100点」まで、合計101個の「バケツ」(実際には配列)を用意します。このバケツを「カウント用配列」と呼びます。 最初はすべて空(カウントが0)です。
カウント用配列 (counts): [ 0(0点), 0(1点), 0(2点), ..., 0(100点) ] (サイズは101)
ステップ2:計数 (Counting)
次に、ソートしたい元の配列 [ 75, 50, 80, 50, 95, 75 ] を先頭から順番に見ていきます。そして、対応する点数のバケツのカウントを1つ増やします。
75を見る → カウント用配列の 75番目 を +1counts[75]が1になる
50を見る → カウント用配列の 50番目 を +1counts[50]が1になる
80を見る → カウント用配列の 80番目 を +1counts[80]が1になる
50を見る → カウント用配列の 50番目 を +1counts[50]が2になる
95を見る → カウント用配列の 95番目 を +1counts[95]が1になる
75を見る → カウント用配列の 75番目 を +1counts[75]が2になる
全てのデータを見終わると、カウント用配列は以下のようになります。(0の箇所は省略)
カウント用配列 (counts) の集計結果:
counts[50] = 2(50点は2人)counts[75] = 2(75点は2人)counts[80] = 1(80点は1人)counts[95] = 1(95点は1人)
この時点で、75 と 50 を直接比べるような「比較」は一度も発生していないですよね。
ステップ3:出力 (Output)
集計が終われば、ソートは終わったも同然です。 新しい「出力用配列」を用意し、カウント用配列の「0番目(0点)」から「100番目(100点)」まで順番に見ていくだけです。
counts[0](0点) を見る →0。何もしない。counts[1](1点) を見る →0。何もしない。- …
counts[50](50点) を見る →2。「50」を2回、出力用配列に追加。- 出力:
[ 50, 50 ]
- 出力:
- …
counts[75](75点) を見る →2。「75」を2回、出力用配列に追加。- 出力:
[ 50, 50, 75, 75 ]
- 出力:
- …
counts[80](80点) を見る →1。「80」を1回、出力用配列に追加。- 出力:
[ 50, 50, 75, 75, 80 ]
- 出力:
- …
counts[95](95点) を見る →1。「95」を1回、出力用配列に追加。- 出力:
[ 50, 50, 75, 75, 80, 95 ]
- 出力:
- …
counts[100](100点) を見る →0。何もしない。
これでソート完了です。バケツ(カウント用配列)が最初から点数順に並んでいるため、そこから順番に取り出すだけで、自動的にソートされた結果が得られます。
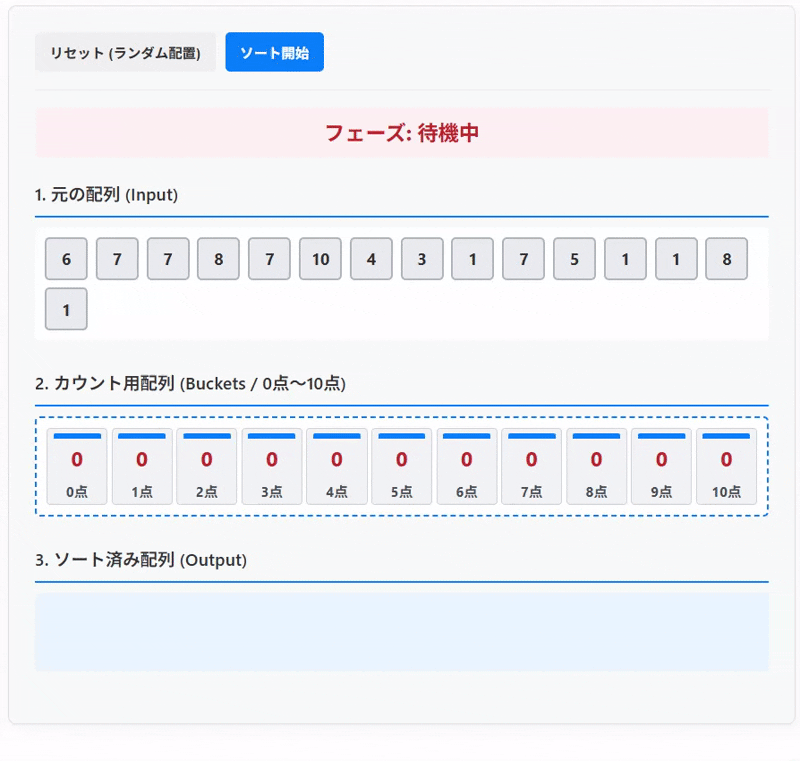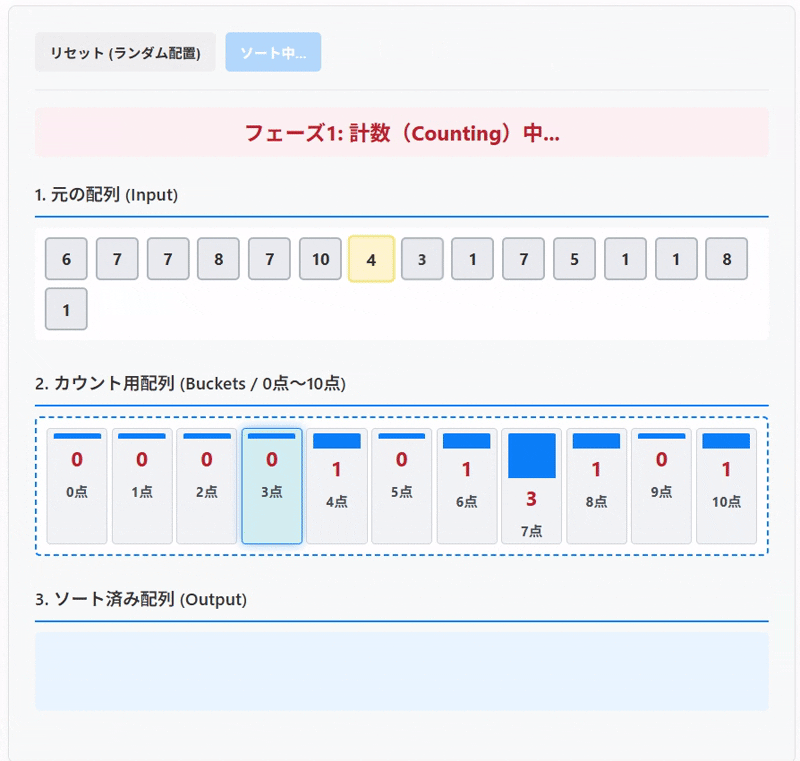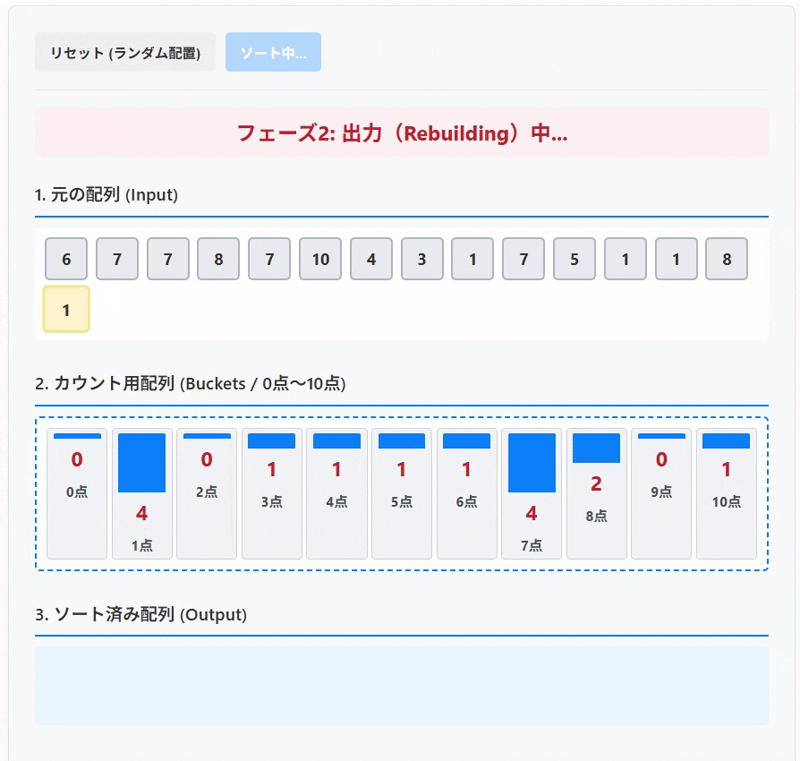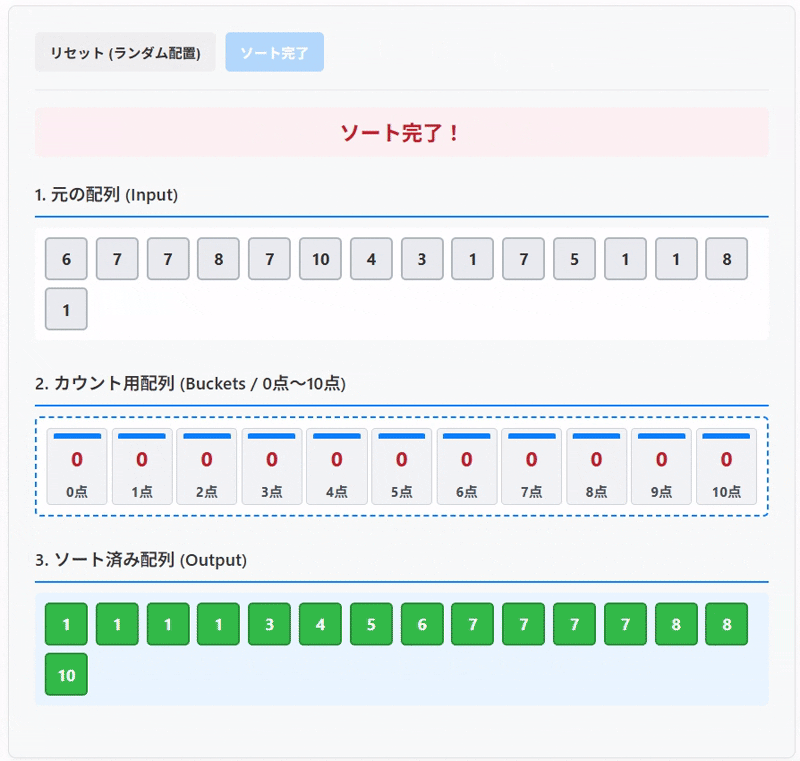
3. カウンティングソートの動きを見てみよう!
カウンティングソートで並び替えを試せます。 「ソート開始」ボタンで配列の要素が対応するバケツ(カウント用配列)に入り、カウント後、バケツの0番から順に取り出されてソート済み配列が完成する様子を観察してみてください。
1. 元の配列 (Input)
2. カウント用配列 (Buckets / 0点〜10点)
3. ソート済み配列 (Output)
4. カウンティングソートの疑似コード (ソートの手順)
このアルゴリズムは、疑似コードにすると非常にシンプルです。
// L: ソートしたいリスト (例: [75, 50, 80...])
// minVal: データの最小値 (例: 0)
// maxVal: データの最大値 (例: 100)
algorithm CountingSort(L, minVal, maxVal) is
k ← maxVal - minVal + 1 // バケツの数 (例: 100 - 0 + 1 = 101)
// 1. 準備: k個のバケツ(counts)を0で初期化
counts ← new Array(k, 0)
// 2. 計数フェーズ
for i from 0 to length(L)-1 do
val ← L[i]
// (例: 50点なら 50 - 0 = 50番目)
index ← val - minVal
counts[index] ← counts[index] + 1
end
// 3. 出力フェーズ
output ← new Array() // 出力用リスト
// minVal(0点)からmaxVal(100点)まで順番にバケツを見る
for i from 0 to k-1 do
// バケツに入っているカウントの回数だけ (例: 50点のバケツに "2" が入っていたら)
for j from 1 to counts[i] do
// その値 (インデックス + 最小値) を出力配列に追加
// (例: 50番目のバケツなら 50 + 0 = 50)
output.append(i + minVal)
end
end
return output
end
(注:これは最も単純な実装です。同じ値の要素の元の順序を保つ「安定ソート」版にするには、カウントを「累積和」にするなど、もう少し複雑な手順が必要になります。)
まとめ
- カウンティングソートは、「比較しないソート」の代表格。
- データの「とりうる値の範囲」の数だけ「バケツ」(カウント用配列)を用意する。
- 「比較」の代わりに「計数(カウント)」を行う。
- 計算量は (O(N+k))。データの範囲 (k) が小さければ、驚異的に速い。
- 弱点として、データの範囲 (k) が非常に大きい(例:0点〜10億点)場合、大量のメモリ(10億個のバケツ)が必要になり、非効率になる。
では、この「データの範囲 (k) が大きい」という弱点を克服しつつ、比較しないソートの速さを活かす方法はないのでしょうか? 次回は、このカウンティングソートを応用した、さらに賢いアルゴリズム「基数ソート(Radix Sort)」を紹介します。
併せて読みたい (基数ソート) カウンティングソートの発展版

ラディックスソート(基数ソート)の仕組みを徹底解説!アニメーションで学ぶ「桁を利用する」ソート【ソートアルゴリズム入門】#14
基数ソートはなぜ速い?カウンティングソートの弱点を「桁ごと」の安定ソートで克服し、O(n log n)の壁を超える仕組みを解説します。
(関連記事) 前の記事 (比較ソートの限界)
O[n log(n)] の壁を超える!「比較しないソート」【ソートアルゴリズム入門】#12
比較しないソートとは?比較ソートの計算量O[n log(n)]を超える別のアプローチについてその導入を紹介します。
 15 記事
15 記事
ソートアルゴリズム
ソートアルゴリズムについて、単純ソート、分割統治法などの比較するソート、基数ソートなどの比較しないソートまでその仕組みを...
ここまで読んでいただきありがとうございます。
では、次の記事で。 lumenHero