計算機を作るためには、ユーザーが入力した「文字の羅列」を、計算機が理解しやすい「単語」として解析する必要があります。今回は、その第一歩である Lexer(字句解析器) の実装について解説します。
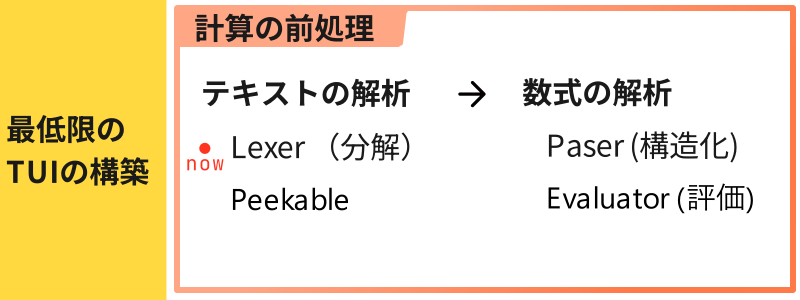
計算機構築までのワークフロー
前回 構想編: 【Rustで作る】ターミナル関数電卓を設計する(アーキテクチャ編) #1
1. Lexerとは?
lexer(字句解析)は、入力された文字列を「トークン」と呼ばれる意味のある単位に分割する処理です。
電卓の場合、数値や演算子(+, -, *, /)、括弧などをそれぞれ独立したトークンとして切り出します。
例えば 12 + 3.5 は、Number(12)、Plus、Number(3.5) のように分解されます。
この段階では構文の正しさや計算は行わず、あくまで「文字列を構造的に扱いやすくする」ことに専念します。
トークン化の思い出(AI)
最近の「トークン化」といえば、Stable Diffusion などの画像生成AIを思い浮かべる方も多いかもしれません。学習データとして画像に詳細な説明(キャプション)を付けたり、特定のキャラクターを学習させるためにタグをちまちまと整理したり……。
あの作業はまさに、AIが理解できる「トークンの塊」を人間が整える工程でした。 ちなみに、画像生成AIには「トークン数の制限(例:200トークン)」があり、いかに効率よく言葉を詰め込むか試行錯誤したのも、今では良い思い出です。
私が初めて「トークン化」という概念に触れたのは、日本語の形態素解析ツール「MeCab」でした。 形態素解析とは、文章を「意味を持つ最小単位(形態素)」、つまり単語や助詞に分解する技術です。
- 入力: 「すもももももももものうち」
- 出力: 「すもも / も / もも / も / もも / の / うち」
この「塊に分ける」という感覚が、まさに今作っている計算機のLexer(字句解析)の発展形といえます。
形態素分析とは、文章を単語や助詞など(形態素)に分解し、解析するというものです。中身を見ると名前がそのままなので覚えやすいですね。
現在のChatGPTなどのLLMも、このトークン化が土台になっています。ただし、最近はMeCabのような単語単位ではなく、文字と単語の中間を巧みに扱う「サブワード(BPEなど)」という手法が主流です。
「意味のない羅列を、意味のある塊へ」。
このシンプルで奥深い処理は、計算機科学のあらゆる場所で息づいています。LLMの仕組みについても、また面白い発見があればまとめてみたいと思います。
2. 実装例
全文載せると長すぎるので、主要な実装部分について説明します。
トークンの定義
トークンは、構造体として定義しました。(取れる値が決まっている intとかfloatとかと同じ)
#[derive(Debug, PartialEq, Clone)]
pub enum Token {
Number(f64), // 64bit浮動小数点
Ident(String), // 関数名や変数名
HistoryRef(usize), // $1, $2 などの履歴参照
Plus, Minus, Star, Slash, Caret, // 演算子 (+, -, *, /, ^)
LParen, RParen, Comma, // 括弧とカンマ
EOF, // 終端記号
}とりあえず、基本的な演算子と履歴からの参照ができるように($)をHistoryRefとして、保持できるようにしています。
数字のNumber(f64),についてですが、f64で64bitの浮動小数点数字を表し、c言語のdouble相当の精度の数字を表せます。f32にしたらfloatになります。
仕組み上はf256とかにしたらめちゃくちゃ高精度に計算できますが、一般的なPCで物理的に計算できるのはf64までなので、これ以上はソフトウェアでエミュレーションする必要があり動作が遅くなります。
クレートで高精度な計算ができるものもあるようですが、いったんはバニラで実装していこうと思います。
高精度計算できるようにするクレートの例
rug(多倍長)bigdecimalnum-bigint
トークナイズ関数
ここで受け取った文字列をトークンに変換しています。EOFにあたるまで、順次前からトークンにできるか検証していくという方法をとっています。
pub fn tokenize(&mut self) -> Result<Vec<Token>, String> {
let mut tokens = Vec::new();
while let Some(token) = self.next_token()? {
if token == Token::EOF {
break;
}
tokens.push(token);
}
tokens.push(Token::EOF);
Ok(tokens)
}トークンにする部分のメイン関数next_token()
Cやほかの言語を使っていると以下のように書きたいところですが、Rustでは、Peekableというイテレータを使うことができ、これを利用すると安全且つ高速化できます。
# こう書きたいところだが、これはRustに向いてない。
fn next_token(&mut self) -> Result<Option<Token>, String> {
self.skip_whitespace();
let curr = match self.peek() {
Some(c) => c,
None => return Ok(Some(Token::EOF)),
};
let token = match curr {
'+' => { self.advance(); Token::Plus }
'-' => { self.advance(); Token::Minus }
'*' => { self.advance(); Token::Star }
'/' => { self.advance(); Token::Slash }
'^' => { self.advance(); Token::Caret }
'(' => { self.advance(); Token::LParen }
')' => { self.advance(); Token::RParen }
',' => { self.advance(); Token::Comma }
'$' => self.lex_history_ref()?,
'0'..='9' | '.' => self.lex_number()?,
'a'..='z' | 'A'..='Z' | '_' => self.lex_identifier()?,
_ => return Err(format!("Unexpected character: {}", curr)),
};
Ok(Some(token))
}Peekableイテレータでは、posなどを保持して、順次処理する方法ではなく、”1文字先読みして判断する”という動作を簡単に実装できます。
fn next_token(&mut self) -> Result<Option<Token>, String> {
self.skip_whitespace();
// Peek で次の一文字を確認(消費はしない)
let curr = match self.chars.peek() {
Some(&c) => c,
None => return Ok(Some(Token::EOF)),
};
let token = match curr {
'+' => { self.advance(); Token::Plus }
'-' => { self.advance(); Token::Minus }
'*' => { self.advance(); Token::Star }
'/' => { self.advance(); Token::Slash }
'^' => { self.advance(); Token::Caret }
'(' => { self.advance(); Token::LParen }
')' => { self.advance(); Token::RParen }
',' => { self.advance(); Token::Comma }
'$' => self.lex_history_ref()?,
'0'..='9' | '.' => self.lex_number()?,
'a'..='z' | 'A'..='Z' | '_' => self.lex_identifier()?,
_ => return Err(format!("Unexpected character: {}", curr)),
};
Ok(Some(token))
}‘0’..=’9′ | ‘.’ => self.lex_number()?,
‘a’..=’z’ | ‘A’..=’Z’ | ‘_’ => self.lex_identifier()?,
ここでそれぞれ数字と関数に割り当てられているかを関数に受け渡し、検証しています。
3.トークナイズの検証
mainでの呼び出しは以下のようにしており、とりあえずtoken分離できるかテストしてみました。
# 自作lexerのインポート mod lexer; これだけでインポート出来て楽。
let mut lexer = lexer::Lexer::new(&self.input);
let mut res_val = format!("none");
match lexer.tokenize() {
Ok(tokens) => {
// トークンの数を確認してみる
res_val = format!("Tokens: {:?}", tokens);
}
Err(e) => {
res_val = format!("Lexer Error: {}", e);
}
}
# res_valを出力に渡す処理など試しに”10 +1″と入力し、実行結果は以下の通りです。
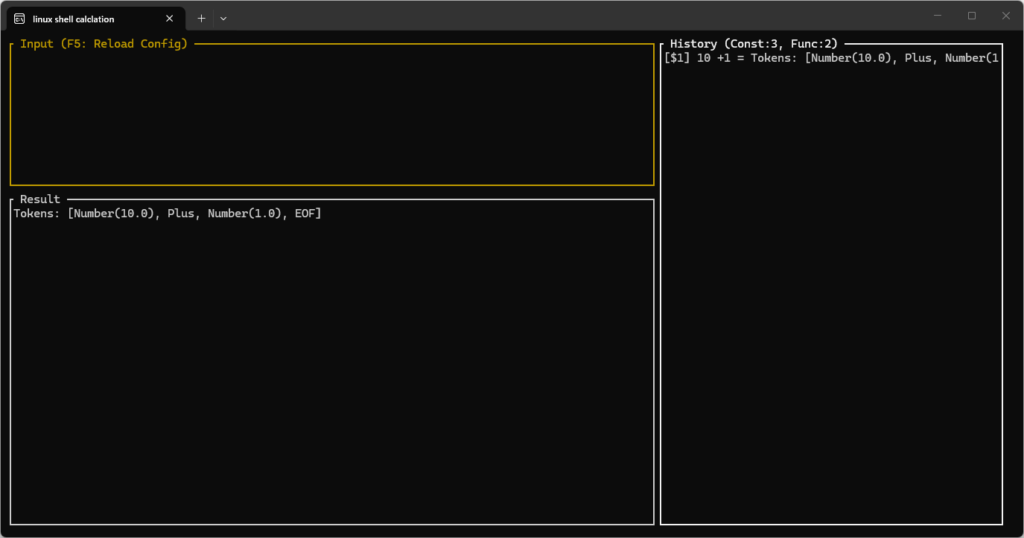
数字はNumber,+は Plusに置き換えられておりうまく動いているようです。
関数に読み替える仕組みは実装していませんが、”test”などのテキストを打ち込むと、Indentとして処理します。
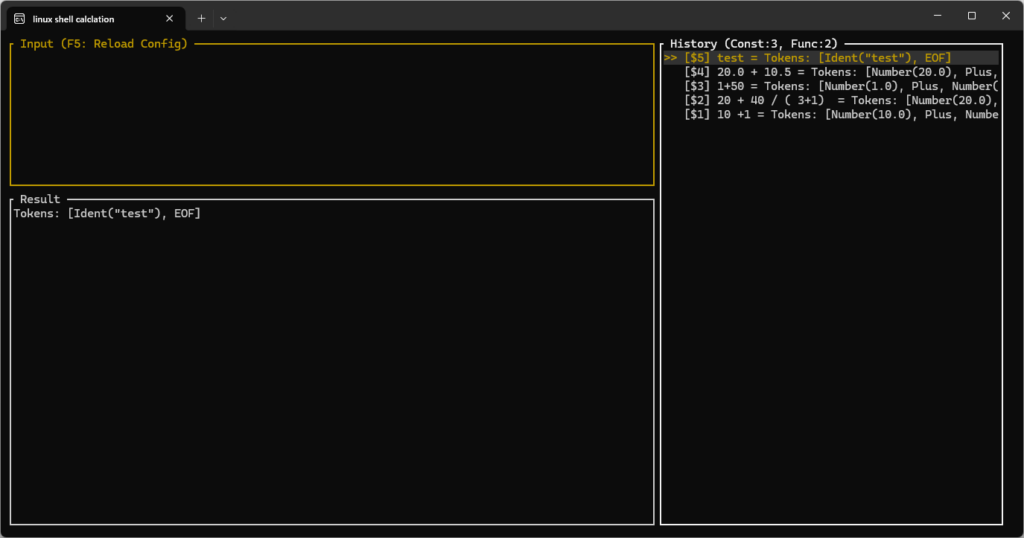
4. トークン化はできた
今回の実装で、基本的な演算子については、トークン化できました。次回は、関数の読み込み(.tomlファイル参照)を実装し、この関数に定義されているものに基づいて解析する仕組みを作っていこうと思います。
次回 (.toml設定ファイルの読み込み) : 【Rust】TOMLで関数を自由に追加!自作電卓に設定読み込みとホットリロードを実装する #3