今回はlogの実装をしてみようと思います。対数は基本となる自然対数のln(n)、2を対数の底とするlog2(n)と任意の底を持てるlog(n,m),を実装します。
大まかな実装手順としては、log2(浮動小数点数なら仮数部分)から実装し、任意の底 \(y\) を持つ対数 \(\log_y(x)\) を計算機で実装する場合、基本的には「底の変換公式」を用いて、自然対数 \(\ln\)(または \(\log_2\))の計算に帰着させて計算するという手順で実装していこうと思います。
\[\log_y(x) = \frac{\ln(x)}{\ln(y)}\]
以前も活用してたbit演算が、この \(\ln(x)\) を求める際の「範囲縮小(Range Reduction)」というステップで真価を発揮します。
1. 浮動小数点の仕組みからlog2を実装する
対数計算において、コンピュータ(2進数世界)が最も得意とするのが \(\log_2\) です。なぜなら、浮動小数点数の内部構造そのものが、すでに対数の答えを半分持っているようなものだからです。
浮動小数点数の「中身」を覗く
私たちが普段使う f64やf32は、浮動小数点数です。(IEEE 754形式,doubleと同等)桁数が多いと図示しづらいのでf16(16桁,16bitの浮動小数点数)で例示すると、各ビットの内訳は、以下の図のような構造になっています。(IEEE 754準拠なので、bfloat16(指数部分が8桁)などとは少し違いますが仕組みは同じです)
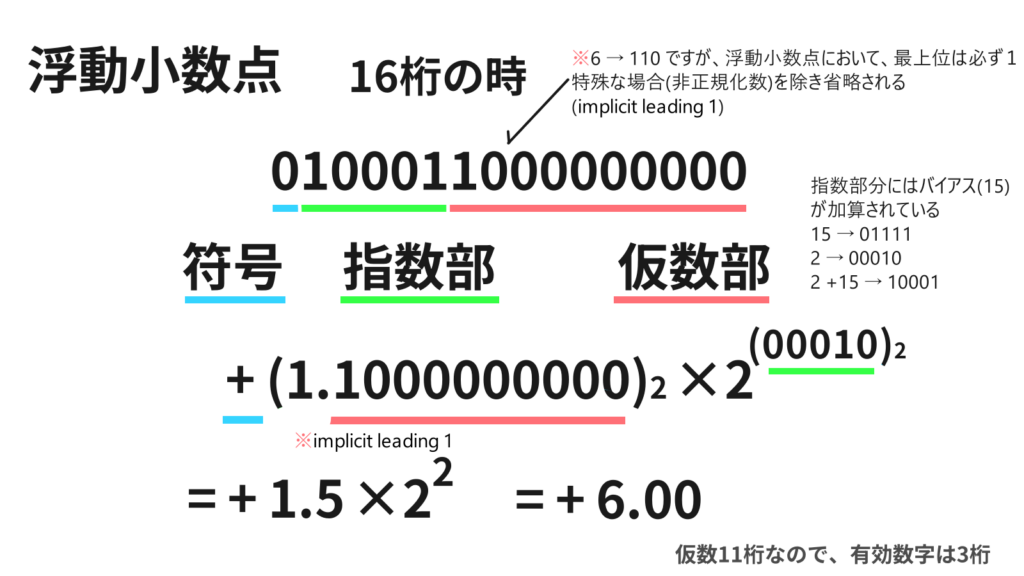
| 項目 | ビット数 | 役割 |
| 符号部 (\(s\)) | 1 bit | 0なら正、1なら負を表します。 |
| 指数部 (\(e\)) | 5 bits | 数値の大きさを決定します。正負の値を表すため表現にバイアス(15)を用いている。 |
| 仮数部 (\(f\)) | 10 bits(11 bits) | 数値の有効数字を保持します。 |
この構造を数式で表すと、数値 \(x\) は \(m \times 2^k\)(\(1 \le m < 2\))と表現されています。これに \(\log_2\) を適用すると……
\[\log_2(x) = \log_2(m \cdot 2^k) = k + \log_2(m)\]
なんと、ビット列から「指数部 \(k\)」を引っこ抜き、バイアスを差し引くだけで、対数の整数部分が求まってしまうのです。あとは、残った「仮数部 \(m\)」の対数を計算するだけで済みます。

例に挙げた log2(6.0)を指数の仕組みを利用して計算してみる。
このビット操作をもとに計算してみると、(1.1)2 = (1,5)10 なので
(10)2 + log2(1.5) = 2 + 0.58496250072.. = 2.58496250072.. = log2(6)
となり、log2(6)と一致することを確認できます。ビットを分離することで、広大な数値範囲を計算する苦労から解放され、[1,2) (\(1 \le m < 2\)) という小さな箱の中だけを考えれば良くなるわけです。
2. ステップ1:log2(x) を実装する
まずは、このビット操作を活用して \(\log_2\) を単体で実装してみます。
指数と仮数の分離(ビット演算ハック)
fn frexp_manual(x: f64) -> (f64, i32) {
let bits = x.to_bits();
// 指数部を抽出してバイアス(1023)を引く。これがほぼ log2(x) の整数部分と一致。
let k = ((bits >> 52) & 0x7FF) as i32 - 1023;
// 指数部を 1023 に書き換えて、仮数部 m (1.0 <= m < 2.0) を復元する
let m_bits = (bits & 0x000FFFFFFFFFFFFF) | (1023 << 52);
let m = f64::from_bits(m_bits);
(m, k)
}
log2 の完成
仮数部 \(m\) は \(1 \le m < 2\) の範囲にあるので、後述する級数展開を使って \(\ln_kernel(m)\) を求め、それを \(\ln_kernel(2) = 1\) で割れば \(\log2(m)\) が出ます。(※lnをカーネル(コア部分)にしているのは、後々するテイラー展開がきれいになる為です。)
pub fn custom_log2(x: f64) -> f64 {
if x <= 0.0 { return f64::NAN; }
let (m, k) = frexp_manual(x); //先ほどの仮数と指数の分離関数
// log2(x) = k + log2(m)
// log2(m) = ln_kernel(m) / ln_kernel(2)
let ln_m = ln_kernel(m);
// 最後に 1/ln(2) を掛けて log2 に変換
// ln_kernel(2) = LOG2_RECIPROCAL は定数になるのであらかじめ計算しておく(または組み込みの定数を利用する)。
// k は整数なので誤差なし、ln_m * LOG2_RECIPROCAL だけが近似
(k as f64) + (ln_m * LOG2_RECIPROCAL)
}※実装上の注意メモ:rustおよび、低レベル実装では、constで定数定義するのが最適です。(const LOG2_RECIPROCAL … など) これは、コンパイル時にその値が使用箇所に「コピー(インライン展開)」されるので、最適化されやすいためです。また、今回使用するようなよく使う定数は、rustならそもそもあらかじめ以下のように定義されていたりします。
// すでに定義されている定数
// consts::LN_2 => 0.6931471805599453
// consts::LOG2_E => 1.4426950408889634 (これが 1/ln(2) と等価)3. ステップ2:一般的な底への拡張(log_y)
\(\log_2\) という「計算機の基本単位」が実装できれば、そこから先は高校数学の知識で世界が広がります。
底の変換公式
任意の底 \(y\) を持つ \(\log_y(x)\) を求めたい場合、すでに手元にある \(\log_2\)(または \(\ln\))を使って以下のように変換できます。
\[\log_y(x) = \frac{\ln(x)}{\ln(y)} \quad \text{または} \quad \frac{\log_2(x)}{\log_2(y)}\]
計算機の実装としては、すべての対数を一度 自然対数 (\(\ln\)) に変換して計算するのが一般的です。(log2を直で求めるのは展開が少し複雑になる為)
4. 補完:ln(m) の級数展開 (ln_kernelの実装)
ここまでの処理で、すべての対数計算を定数とln_kernelのみに分解できました。ビット演算で \(x\) を \([1, 2)\) の範囲まで追い込んだら、最後の仕上げは級数展開です。
\[z = \frac{m-1}{m+1}\]
とおいて、以下の級数(奇数項のみ)を計算します。これが最も収束が早く、高精度です。
\[\ln(m) = 2 \left( z + \frac{z^3}{3} + \frac{z^5}{5} + \dots \right)\]
これは、単純なマクローリン展開の弱点である「収束の遅さ」を克服し、さらに偶数項をまるごと消し去るための数学的な工夫です。マクローリン展開がわかる人は手元で計算してみると確かめられると思います。
「なぜこれで \(\ln(m)\) が求まるの?」「どうして奇数項だけになるの?」という数理的な証明は、別記事に詳しくまとめました。
解説記事 なぜわざわざ zに置換したの?: ln自然対数の計算プログラム実装でzに置換する理由【ホーナー法・グレゴリー級数】
Rustによる最終的な汎用実装
pub fn ln_kernel(x: f64) -> f64 {
if x <= 0.0 { return f64::NAN; }
let (m, k) = frexp_manual(x);
let z = (m - 1.0) / (m + 1.0);
let z2 = z * z;
let mut sum = 0.0;
// f64の有効数字は17桁なので12項目まで計算すれば十分。
// ホーナー法で実装
for i in (0..12).rev() {
sum = 1.0 / (2 * i + 1) as f64 + z2 * sum;
}
let ln_m = 2.0 * z * sum;
// 最終結果: k * ln(2) + ln(m)
(k as f64).mul_add(0.6931471805599453, ln_m)
}
pub fn custom_log_x_y(x: f64, y: f64) -> f64 {
ln_kernel(x) / ln_kernel(y)
}計算のテスト
今回実装した関数と、標準で搭載されているlogの計算を行い比較してみました。
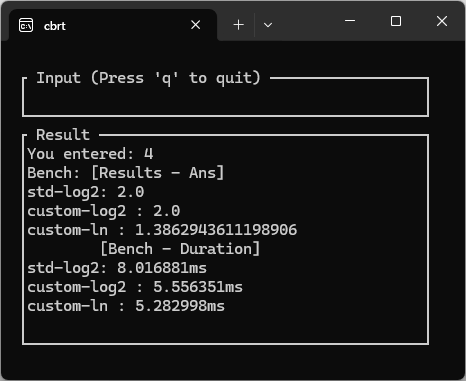
速度比較すると、体感はできないでしょうが、自作関数の方が早いようです。(読み込みのヘッドロスの方が影響が大きいと思われますが)
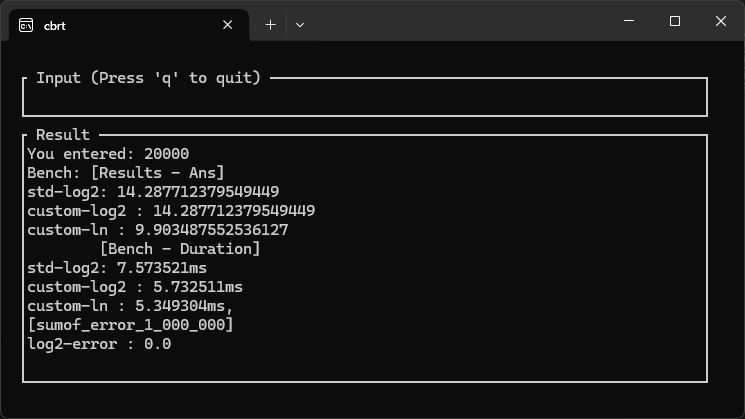
画像:f64精度では同等の精度を出せている
custom_log2の計算結果をstdのlog2と比較し差をを合計している log2_errorも
1万回回しても0.0なので実用的には問題がない精度であることを確認。
※条件を同じにするために同一ファイルに書き込み呼び出す形で検証しています。x.ln()のように直で呼べば、マイクロ秒レベルになりstdが最速になります。
まとめ:今回の「ハック」のポイント
- log2は「取り出す」もの: 浮動小数点数の指数部 \(k\) を取り出すだけで、対数の大部分は計算が終わっている。
- 範囲縮小: 級数展開の弱点(入力が1から離れると遅い)を、ビット演算で強制的に\([1, 2)\) に押し込めることで克服した。
- 底の変換: 基礎となる対数さえ高精度に作れば、あとは割り算ひとつでどんな底にも対応できる。
最初は魔法のように見えるビット演算も、IEEE 754の構造を知れば、非常に理にかなった「効率化の極致」であることが分かりますね。
実装上の注意点ともっと早くする方法
- \(x \approx 1\) の付近: \(x\) が \(1\) に非常に近い場合、ビット分離をせずに直接 \(\ln(1+d)\) の近似式を使ったほうが精度(ULP誤差)が良くなることがあるようです。
- ホーナー法では順次処理ですが、エストリン法という方法をとればある程度並列化できて高速化できる場合があるようです。
- 精度のトレードオフ: 標準関数(std)はさらにここから「多項式近似(Remezのアルゴリズム)」や「ルックアップテーブル」を組み合わせて、ループを完全に排除した実装になっているらしい。
次回は理論面(マクローリン展開)は今回と同様ですが、計算手順を効率化したエストリン法での実装を行い、比較検証してみようと思います。
次回 エストリン法と比較:【最適化編】ホーナー法を超えて:エストリン法による対数計算の並列化 #16
では、次の記事で。 lumenHero
関連記事
第7回 Evaluatorの実装 :【Rust】計算機自作:演算と比較を評価するEvaluatorの実装(式指向の設計) #7
第11回 平方根の計算実装:【Rust自作TUI電卓】mod.rsを活用したスマートなモジュール管理と基本数学関数の実装 #11
第13回 n乗根の計算実装:【Rust自作TUI電卓】ニュートン法×マジックナンバーで実装する汎用n乗根 #13
第14回 ハレー法による立方根:【Rust自作TUI電卓】ニュートン法を超えろ!ハレー法による立方根(cbrt)の極限最適化 #14
バビロニア法・ニュートン法:平方根の導出展開、手動でも解ける差分アプローチ【バビロニア法・ニュートン法】