TUI電卓実装プロジェクトの対数関数の実装では、級数展開を高速化するために「ホーナー法」というテクニックを使用しました。
\[ax^n +bx^{n-1}+cx^{n-2}+\dots +αx+β \]
\[=x(\dots (x(x(ax +b)+c)) \dots + α) +β \]
多項式の計算において、この手法は単なる「見た目の書き換え」以上の意味を持ちます。特に低レイヤーの最適化やハードウェアの特性を理解する上で、ホーナー法は避けては通れない非常に奥深いトピックです。
今回は、文字列解析のローリングハッシュ問題にもよくつかわれるなじみ深い手法でもあるホーナー法の仕組みから、現代のCPUが持つ強力な命令との相性、そしてその弱点までを徹底的に解説します。
1. ホーナー法とは?:多項式を「入れ子」にする
多項式の計算を普通に行おうとすると、各項でべき乗(\(x^n\))の計算が発生します。例えば、3次多項式を愚直に計算すると以下のようになります。
\[P(x) = a_3 x^3 + a_2 x^2 + a_1 x + a_0\]
これを計算機でそのまま実行すると、掛け算が6回(\(x \cdot x \cdot x\) など)、足し算が3回必要になります。
一方、ホーナー法では多項式を次のように「入れ子(ネスト)」の形に変形します。
\[P(x) = ((a_3 x + a_2) x + a_1) x + a_0\]
この変形により、必要な演算は掛け算3回、足し算3回へと劇的に減少します。\(n\)次多項式であれば、乗算と加算がそれぞれちょうど \(n\) 回ずつで済むという計算効率の極致とも言える手法なのです。
2. 低レイヤーにおけるメリット:FMAの力を引き出す
掛け算と足し算の回数を \(n\) 回に減らせるだけでも十分効率化できていますが、現代のCPUには、FMA (Fused Multiply-Add) という非常に強力な命令が搭載されています。FMAは、「掛け算して足す(\(a \times b + c\))」という演算を、ひとつの命令(1クロック)で同時に処理します。
ホーナー法の形をよく見ると、すべてのステップが (前の結果 * x) + 係数 という「掛け算 + 足し算」の形になっていることが分かります。
Rustで実装する場合、mul_add メソッドを使用するとコンパイラが自動的にこのFMA命令(vfmadd213ss など)を割り当てます。
FMAを使うメリットは2つあります:
- 高速化: 2つの演算を1回で終わらせる。
- 高精度: 掛け算のあとの丸めをスキップし、最後に一度だけ丸めるため、通常の
+と*を分けるよりも誤差が少なくなります。
2.1 速度検証コード
以下のような20次元の多項式計算で、1万回回しベンチマークをとってみました
// 20次多項式の係数 (a20, a19, ..., a0)
const COEFFS_20: [f64; 21] = [
0.1, -0.2, 0.3, -0.4, 0.5, -0.6, 0.7, -0.8, 0.9, -1.0,
1.1, -1.2, 1.3, -1.4, 1.5, -1.6, 1.7, -1.8, 1.9, -2.0, 2.1
];
/// 20次 Naive
pub fn naive_20(x: f64) -> f64 {
let mut res = 0.0;
for i in 0..=20 {
// COEFFS_20[0] が x^20 に対応するようにアクセス
res += COEFFS_20[i] * x.powi((20 - i) as i32);
}
res
}
/// 20次 Horner (Loop)
pub fn horner_loop_20(x: f64) -> f64 {
let mut res = COEFFS_20[0];
for i in 1..21 {
res = res * x + COEFFS_20[i];
}
res
}
/// 20次 Horner (FMA)
pub fn horner_fma_20(x: f64) -> f64 {
let mut res = COEFFS_20[0];
for i in 1..21 {
res = res.mul_add(x, COEFFS_20[i]);
}
res
}2.2 速度検証結果
以下のような20次元の多項式計算で、1万回。計算を回しベンチマークした結果は以下のようになり、horner法が圧倒的に早いということが確認できました。
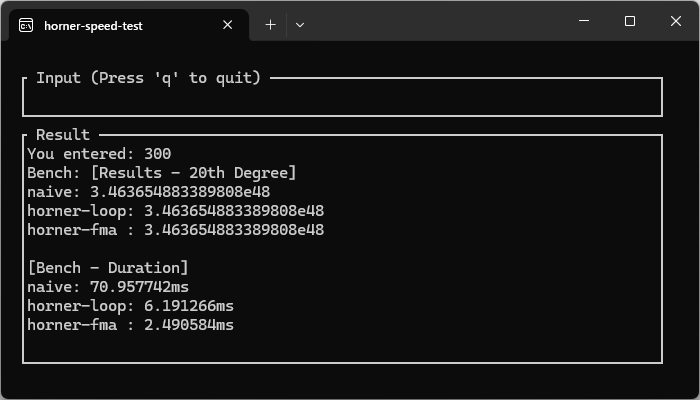
このように、約71msから約2.5msへと28倍も高速化できています。
※検証上の注意、もし同じような検証をするときは、”–release”と”native”指定しないと、mul_addがエミュレータでの計算になり、結果的に遅くなることがあります。
コンパイル時は、cargo runだけの実行(degug環境)ではなく、cpu準拠でリリース引数付きでコンパイルする必要があります。
RUSTFLAGS="-C target-cpu=native" cargo run --release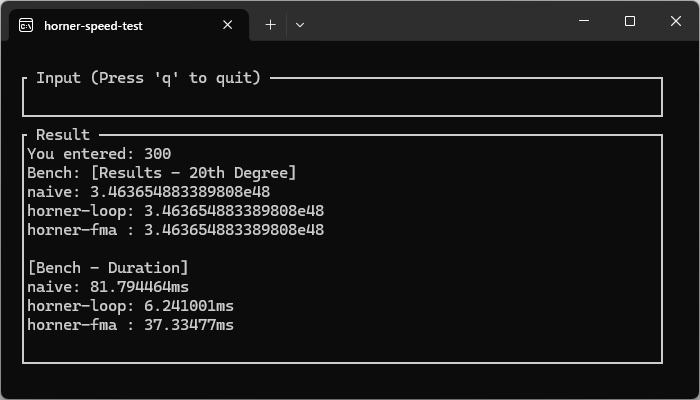
エミュレータでの計算で遅くなった例
3. ホーナー法の弱点:データ依存性の壁
「最強の計算手法」に見えるホーナー法ですが、現代の高速なプロセッサにおいては「データ依存性」という弱点が露呈します。
ホーナー法の計算順序は、最も内側のカッコが終わらない限り、その外側の計算を始めることができません。つまり、CPUがどれだけ「同時に複数の命令を処理できる(スーパースカラ)」能力を持っていても、ホーナー法では1列に並んで順番に計算を待つしかないのです。
これを「シリアルな実行(Sequential Execution)」と呼び、CPUの並列処理能力をフルに活かせない原因となります。
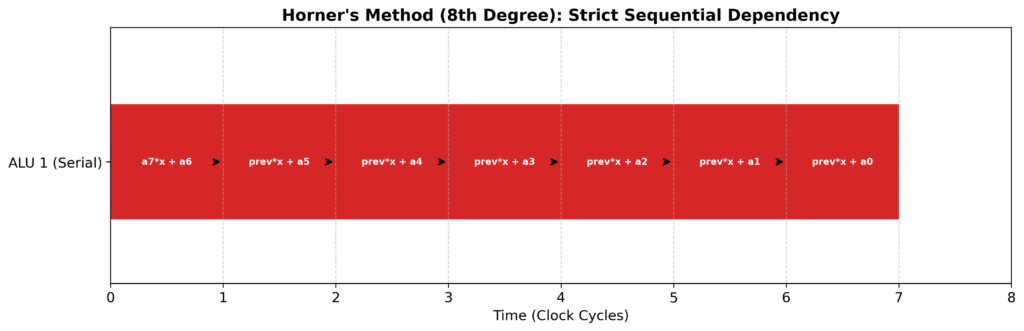
ホーナー法の処理イメージ
5. これよりも効率化するには?:その先の技術
ホーナー法は多項式計算の基本ですが、実際の数値計算ライブラリ(std::f64::log など)では、さらに高度な技術が組み合わされています。
エストリン法 (Estrin’s Scheme)
ホーナー法の「データ依存性」を解決するために、多項式をツリー状に分割して計算します。これにより、複数の計算ユニットを同時に働かせることができ、非常に項数が多い場合にホーナー法を追い抜くことがあります。
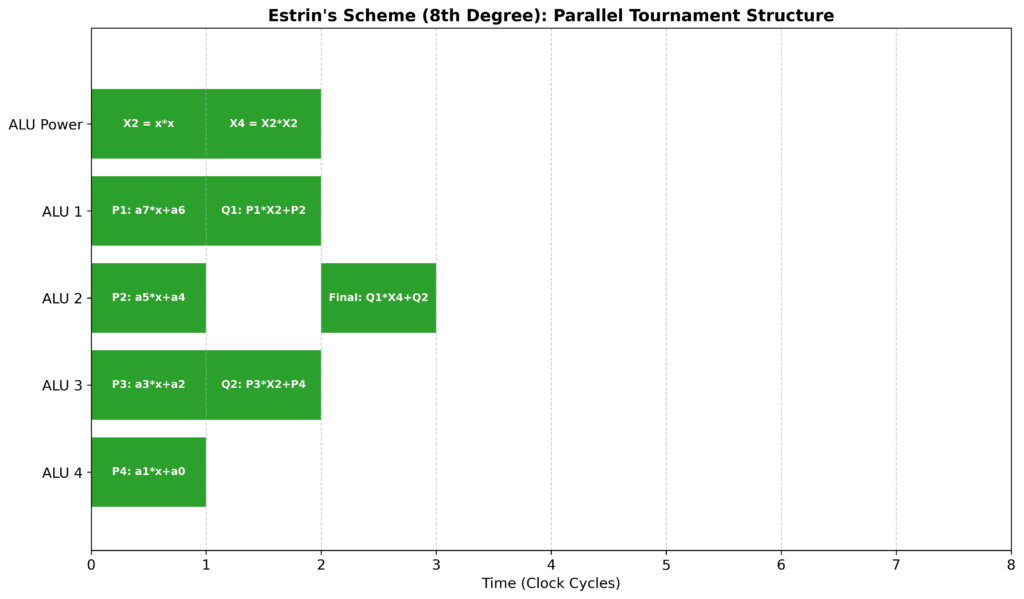
ホーナー法による処理イメージ(並列化できる)
チェビシェフ多項式と近似
これまでの記事で扱ってきたのは「テイラー展開」による多項式でしたが、実は計算範囲全体で誤差を均一にするには、チェビシェフ多項式を用いた近似(Remezのアルゴリズム)の方が効率が良いことが知られています。
(そのうち、時が来たら解説予定です (予定地))
まとめ:電卓開発におけるホーナー法
私が作っているTUI電卓の裏側では、\(\log\) や \(\sin\)、\(\sqrt{x}\) といった複雑な関数がすべて「多項式」へと分解されています。その心臓部である計算を、いかにCPUの特性(FMAなど)を活かして高速に回すか。
ホーナー法は、「数学的なシンプルさ」と「ハードウェアの最適化」が交差する、最高に面白いポイントです。
たったひとつの「カッコの付け替え」が、計算機の世界では劇的な変化を生む。とても興味深い現象ですね。より高次元の計算だと場合によっては、エストリン法を用いて並列化するとより高速化できたりします。
エストリン法と比較してみた:【多項式計算の最適化】ホーナー法と、並列処理に強い「エストリン法」の比較検証
ここまで読んでいただきありがとうございます。
では、次の記事で。 lumenHero
関連記事:計算プログラムの手法いろいろ
第7回 Evaluatorの実装 :【Rust】計算機自作:演算と比較を評価するEvaluatorの実装(式指向の設計) #7
第11回 平方根の計算実装:【Rust自作TUI電卓】mod.rsを活用したスマートなモジュール管理と基本数学関数の実装 #11
第13回 n乗根の計算実装:【Rust自作TUI電卓】ニュートン法×マジックナンバーで実装する汎用n乗根 #13
第14回 ハレー法による立方根:【Rust自作TUI電卓】ニュートン法を超えろ!ハレー法による立方根(cbrt)の極限最適化 #14
バビロニア法・ニュートン法:平方根の導出展開、手動でも解ける差分アプローチ【バビロニア法・ニュートン法】