前回の記事では、350年前の知恵「グレゴリー級数」を紐解きました。理論としては完璧ですが、いざ現代の爆速CPUで実行してみると、一つの大きな壁にぶつかります。
それは、折角マルチコアのCPUが使えるのに「前の計算が終わるまで次へ進めない」という、逐次処理の呪縛です。
今回は、計算順序を「数珠つなぎ」から「トーナメント形式」に変えることで、CPUの真の力を引き出すエストリン法(Estrin’s scheme)を実装していきます。
1. ホーナー法の限界:データ依存の鎖
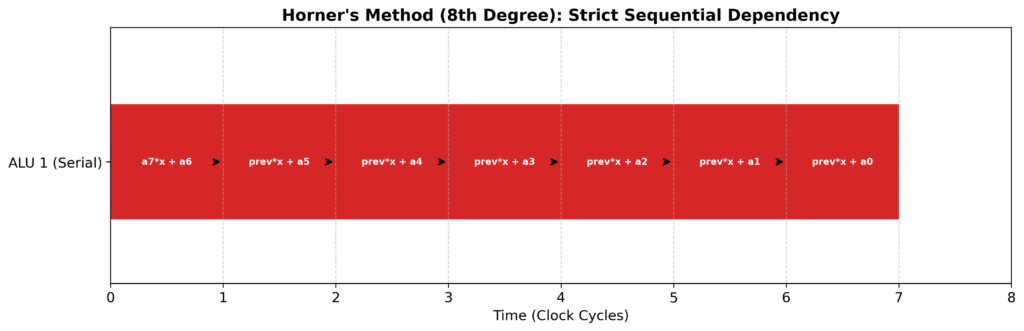
これまでの実装(ホーナー法)は、多項式を \(a + x(b + x(c + \dots))\) と計算していました。
これは非常に効率的に見えますが、ハードウェアの視点で見ると「前の積算が終わるまで、次の加算ができない」というデータ依存の鎖が生じています。
ハレー法の処理イメージ
現代のCPUは、演算器(ALU)を複数積んでおり、手が空いていれば並列に仕事をこなしたいと考えています。しかし、ホーナー法では一人の作業員(ALU 1)だけが「前の計算結果待ち」で過労死する勢いで働き、他の作業員は遊んでいる状態なのです。まさに計算界のブラック企業……「ALU 1:フェアじゃない!俺だけブラックだ!」という悲鳴が聞こえてきそうです。
エストリン法の処理イメージ
2. エストリン法:演算器を総動員する
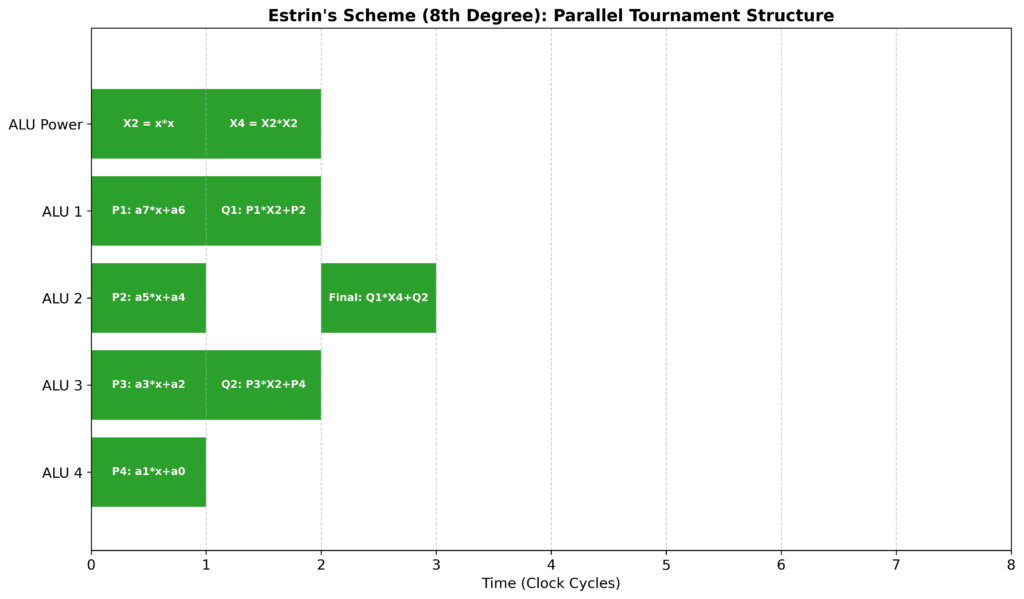
そこで登場するのがエストリン法です。多項式を\(x^2\)で括りだすように「ペア」に分け、ツリー状に計算を進めます。プログラミングでおなじみの「分割統治法」に近いイメージですね。
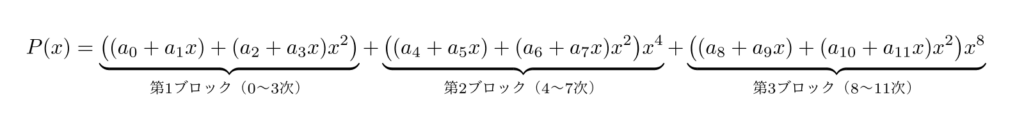
この構造の最大のメリットは、各ブロックの計算がすべて互いに独立している点です。
CPUの「スーパースケーラ」機能により、複数のALUが同時に動き出し、理論上、計算時間はツリーの高さ(対数的)に短縮されます。
解説 エストリン法:【多項式計算の最適化】ホーナー法と、並列処理に強い「エストリン法」の比較検証
3. Rustによる実装:ln_kernel_estrin
Rustの mul_add を使い、明示的に並列性を意識したコードへ書き換えます。
// コードの概要:実際の実装は定数をあらかじめコンパイル時に計算させるなどしています。
pub fn ln_kernel_estrin(m: f64) -> f64 {
let z = (m - 1.0) / (m + 1.0);
let z2 = z * z;
let z4 = z2 * z2;
let z8 = z4 * z4;
// 係数:理論的なグレゴリー級数の値 (1/(2i+1))
let c = [
1.0, 1.0/3.0, 1.0/5.0, 1.0/7.0, 1.0/9.0, 1.0/11.0,
1.0/13.0, 1.0/15.0, 1.0/17.0, 1.0/19.0, 1.0/21.0, 1.0/23.0
];
// --- Level 1: 並列実行を期待するセクション ---
let p0 = c[1].mul_add(z2, c[0]);
let p1 = c[3].mul_add(z2, c[2]);
let p2 = c[5].mul_add(z2, c[4]);
let p3 = c[7].mul_add(z2, c[6]);
let p4 = c[9].mul_add(z2, c[8]);
let p5 = c[11].mul_add(z2, c[10]);
// --- Level 2: 結合 ---
let q0 = p1.mul_add(z4, p0);
let q1 = p3.mul_add(z4, p2);
let q2 = p5.mul_add(z4, p4);
// --- Level 3: 最終統合 ---
let r0 = q1.mul_add(z8, q0);
let z16 = z8 * z8; // z^16
let sum = q2.mul_add(z16, r0);
2.0 * z * sum
}
4. 精度不足
実装中、特定の値で計算が標準関数と合わない問題に直面しました。これは級数の項数不足ではなく、計算過程で発生する「丸め誤差」が原因です。
これを改善するため、現在の計算範囲 \([1, 2)\) から、最も収束が安定する \([\sqrt{2}/2, \sqrt{2})\) (約 \(0.707 \sim 1.414\)) へ移動(シフト)させます。
範囲を \(1\) の付近にギュッと押し込めることで、丸め誤差の影響を極小化し、12項の実装でも \(10^{-17}\) 級の精度を叩き出すことが可能になりました。
画像:丸め誤差による計算の結果の誤り
5. 実測:ベンチマーク結果
テストコード(1万回テスト)で、従来のホーナー法と比較を行いました。
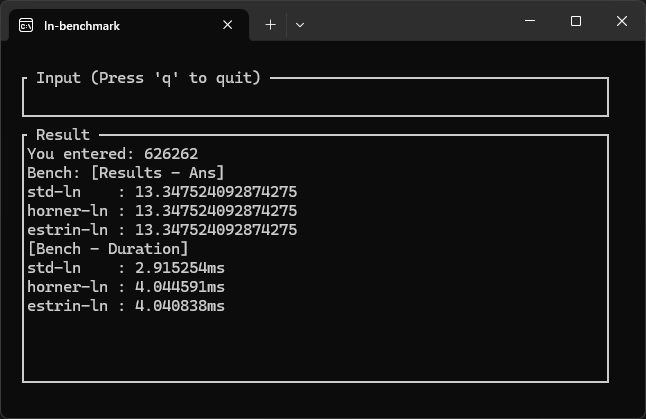
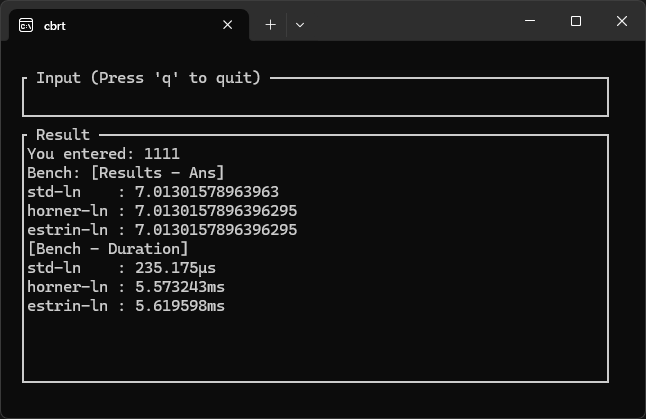
画像:stdが早い例
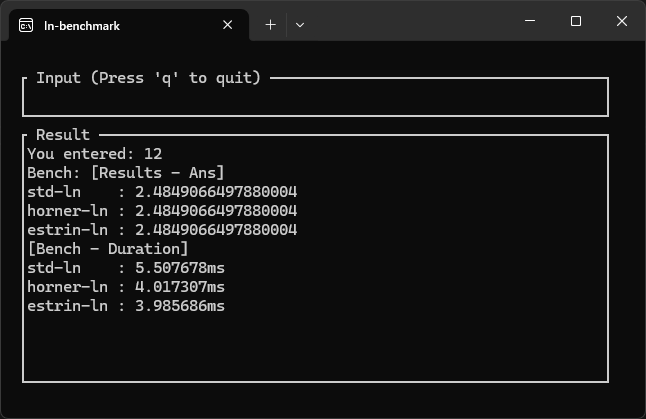
画像:estrinが早い例
| メソッド | 実行時間 (ns) | 速度考察 |
| Std (標準関数) | 2.8 ns ~ 7.0 ns | 値により速度が大きく変わるようです。 |
| Horner (現状) | 3.7 ns ~ 5.5 ns | 移動により前回よりは少し高速化した。 |
| Estrin (今回) | 3.8 ns ~ 5.5 ns | 12次程度では、8乗などの計算の方のコストが高く、高速化できなかった。 |
考察
今回の 12次〜14次 程度の規模では、エストリン法による並列化の恩恵は限定的でした。CPUの演算能力よりも、追加のべき乗(\(z^8, z^{16} \))を計算するコストやレジスタの圧力の方が重かったようです。
一方、std の実装は特定の値で超高速になりますが、自作関数の方が安定して 4〜5ns をマークする場面もあり、「安定した自作ライブラリ」 としての可能性が見えました。結果として、今回は構造がシンプルなホーナー法をベースに採用することにしました。
結び:理論の次は「最強の係数」へ
エストリン法による「手順の最適化」を試みたことで、現代のCPUと対話する楽しさを味わえました。しかし、私たちの log_tk にはまだ弱点があります。それは、「理論値そのままの係数(1/3, 1/5…)を使っている」という点です。
次回の最終章では、いよいよ数学と計算機の妥協点を探る「Remezのアルゴリズム」を導入します。理論上の \(1/3\)などの奇数の逆数を超える、計算機にとっての「真の最良」を見つけ出し、標準ライブラリ std::f64::ln という巨人に挑みます。
次回 Remezのアルゴリズム: 【Rustで作る電卓】Remezのアルゴリズムでlog計算を最適化 #17
ここまで読んでいただき、ありがとうございました。
では、次の記事で。 lumenHero
関連記事
第7回 Evaluatorの実装 :【Rust】計算機自作:演算と比較を評価するEvaluatorの実装(式指向の設計) #7
第11回 平方根の計算実装:【Rust自作TUI電卓】mod.rsを活用したスマートなモジュール管理と基本数学関数の実装 #11
第13回 n乗根の計算実装:【Rust自作TUI電卓】ニュートン法×マジックナンバーで実装する汎用n乗根 #13
第14回 ハレー法による立方根:【Rust自作TUI電卓】ニュートン法を超えろ!ハレー法による立方根(cbrt)の極限最適化 #14
第15回 logの計算基本編:【Rustで作る電卓】浮動小数点数の構造をハックして対数関数(log)を実装する #15
バビロニア法・ニュートン法:平方根の導出展開、手動でも解ける差分アプローチ【バビロニア法・ニュートン法】
解説 ホーナー法:ホーナー法とは?多項式計算の効率化手法そのメリットとデメリット
解説 エストリン法:【多項式計算の最適化】ホーナー法と、並列処理に強い「エストリン法」の比較検証