前回は正接関数(tan)をフルスクラッチ実装してみました。ランベルトの連分数展開を用いて極(\(\pi/2\)など)でも少ない項数で精度よく近似することができました。
今回は、前回の理論に忠実な実装ではf64::tanと比べて約8倍程度遅いため、多項式に分解したりホーナー法 + FMAでマシンフレンドリーな実装にすることで高速化していこうと思います。
前回 tanの実装:【Rustで作る電卓】ランベルト(Lambert)の連分数展開でtan(正接)を実装 三角関数の実装(5) #22

1. 多項式にする
前回の実装では、ランベルトの連分数展開をそのまま実装していましたが、これだと項数の数だけ割り算をしないといけません。コンピュータの計算において割り算は掛け算などと比べて重たい処理なので、できるだけ少なくしたいところです。
\[\tan x = \cfrac{x}{1 – \cfrac{x^2}{3 – \cfrac{x^2}{5 – \cfrac{x^2}{7 – \dots}}}}\]
前回の式(f64で十分な精度である\(n=13\)まで)について、これを1回の割り算で済むように整理していきます。
1.1. 有理関数形式: \(\tan x \approx \frac{P(x)}{Q(x)}\)
連分数展開を整理すると、\(\tan x\) は以下の有理関数で近似されます。
\[ \tan x \approx \frac{a_1 x + a_3 x^3 + a_5 x^5 + a_7 x^7 + a_9 x^9 + a_{11} x^{11} + a_{13} x^{13}}{b_0 + b_2 x^2 + b_4 x^4 + b_6 x^6 + b_8 x^8 + b_{10} x^{10} + b_{12} x^{12}} \]
(ちなみに、この展開は、数学的には Padé(パデ)近似 と非常に近い形になります。\(n=13\)(分母の最大値が \(2 \times 13 – 1 = 25\))まで展開すると、分子は13次、分母は12次の多項式になります。)
1.2. 係数の算出規則
導出は省略しますが、この多項式の係数 \(a_k, b_k\) は、以下の逆順の漸化式から得られる非常に大きな整数になります。大きすぎる数だと扱いづらく、実用上(f64 精度)は、定数項 \(b_0\) を \(1\) に正規化した係数を用いるのが一般的です。
この正規化された係数は、以下の一般式で表される値に対応しています。
\[ a_{2k+1} = \frac{(-1)^k (2n-2k)! \cdot n!}{ (2n)! \cdot k! \cdot (n-2k)! } \quad (\text{分子}) \]
\[ b_{2k} = \frac{(-1)^k (2n-2k)! \cdot n!}{ (2n)! \cdot k! \cdot (n-2k)! } \quad (\text{分母}) \]
※ \(n=13\) の場合、この公式から得られる値を適切に分子・分母へ振り分けることで、極めて精度の高い近似多項式が構成されます。
詳細な計算プロセスと、巨大な整数から正規化された小数係数への変換過程については、以下の補助資料にまとめました。
補助資料:係数の計算詳細と算出スクリプト (記事は現在利用できません: ID 7696)
1.3 求まった係数
補助資料での計算を経て得られた、\(n=13\) における具体的な正規化係数は以下の通りです。この値を定数として用いることで、\(\tan x\) を高速かつ高精度に計算することが可能になります。
分子 \(P(x) = x \cdot (a_0 + a_1 x^2 + a_2 x^4 + a_3 x^6 + a_4 x^8 + a_5 x^{10} + a_6 x^{12})\)
| 係数 | 値(f64 精度) |
| \(a_0\) | \(1.0\) |
| \(a_1\) | \(-1.466666666667 \times 10^{-1}\) |
| \(a_2\) | \(5.217391304348 \times 10^{-3}\) |
| \(a_3\) | \(-6.625258799172 \times 10^{-5}\) |
| \(a_4\) | \(3.228683625327 \times 10^{-7}\) |
| \(a_5\) | \(-5.179706350793 \times 10^{-10}\) |
| \(a_6\) | \(1.264885555749 \times 10^{-13}\) |
分母 \(Q(x) = b_0 + b_2 x^2 + b_4 x^4 + b_6 x^6 + b_8 x^8 + b_{10} x^{10} + b_{12} x^{12}\)
| 係数 | 値(f64 精度) |
| \(b_0\) | \(1.0\) |
| \(b_1\) | \(-4.800000000000 \times 10^{-1}\) |
| \(b_2\) | \(3.188405797101 \times 10^{-2}\) |
| \(b_3\) | \(-6.625258799172 \times 10^{-4}\) |
| \(b_4\) | \(5.230467473030 \times 10^{-6}\) |
| \(b_5\) | \(-1.519380529566 \times 10^{-8}\) |
| \(b_6\) | \(1.151045855732 \times 10^{-11}\) |
2. ホーナー法(Horner’s method)
このシリーズでは、logの計算で一度出てきましたが、Horner法でコンピュータが1命令で処理できるFMA形式にこの多項式を明示的に記入し、高速化していきます。
2.1 Horner法の例
Horner法を以下の式に適用してみます。
\[P(x) = a_3 x^3 + a_2 x^2 + a_1 x + a_0\]
Horner法では多項式を次のように「入れ子(ネスト)」の形に変形します。
\[P(x) = ((a_3 x + a_2) x + a_1) x + a_0\]
これで掛け算と足し算のセットだけの構成にできます。
こうすることでなぜ早くなるのかの詳細は以前記事にまとめたので、興味があれば覗いてみてください。ホーナー法詳細:ホーナー法とは?多項式計算の効率化手法そのメリットとデメリット
2.2 Horner法でtanを実装
係数をべた書きして、rustでtanを実装してみます。mul_addが連なるようなすっきりした実装になりました。
fn kernel_tan_horner(x: f64) -> f64 {
if x == 0.0 { return 0.0; }
let x2 = x * x;
// 分子 P(x)/x の係数 (a_0 ~ a_6)
const A: [f64; 7] = [
1.0,
-1.466666666667e-1,
5.217391304348e-3,
-6.625258799172e-5,
3.228683625327e-7,
-5.179706350793e-10,
1.264885555749e-13,
];
// 分母 Q(x) の係数 (b_0 ~ b_6)
const B: [f64; 7] = [
1.0,
-4.800000000000e-1,
3.188405797101e-2,
-6.625258799172e-4,
5.230467473030e-6,
-1.519380529566e-8,
1.151045855732e-11,
];
// ホーナー法による多項式評価
// P_poly = a6*x^12 + a5*x^10 + ... + a0
// let p_poly = ((((((A[6] * x2 + A[5]) * x2 + A[4]) * x2 + A[3]) * x2 + A[2]) * x2 + A[1]) * x2 + A[0]);
// と同じだが、明示的にmul_add命令にしている
let p_poly = A[6]
.mul_add(x2, A[5])
.mul_add(x2, A[4])
.mul_add(x2, A[3])
.mul_add(x2, A[2])
.mul_add(x2, A[1])
.mul_add(x2, A[0]);
// Q_poly = b6*x^12 + b5*x^10 + ... + b0
let q_poly = B[6]
.mul_add(x2, B[5])
.mul_add(x2, B[4])
.mul_add(x2, B[3])
.mul_add(x2, B[2])
.mul_add(x2, B[1])
.mul_add(x2, B[0]);
x * (p_poly / q_poly)
}3. 実装結果比較
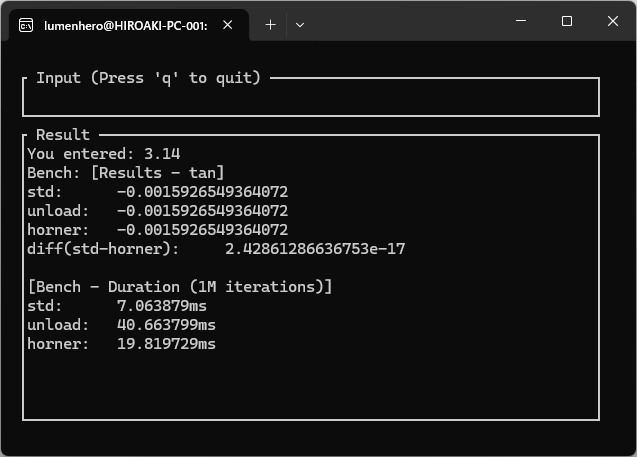
速度を見てみると、19ms~21ms程度になることがわかりました。tanの範囲還元に使っているpayne_hanek法が一回当たり平均17ns、100万で17ms程度となっているため、tanの計算部分は2ms程度に高速化できました。(unrollでは 20ms程度かかっていました)
考察
考察としては、unroll(ランベルトの多項式ほぼそのまま計算)では、割り算がn +1回必要だったのが、多項式にすることで割り算を1回に抑えたこと、FMA命令(1命令で足し算と掛け算を行う)に最適化したことで、コア部分の計算を12回命令に圧縮できたことでこれだけの高速化ができたのだと考えられます。
mul_addの方が遅くなる?
Rust(LLVM)のコンパイラでは、–releaseをつけることでエミュレータではなくできる限り高速に最適化してくれます。LLVMは (a * b + c) というパターンを見つけると、ターゲットCPUが対応していれば自動的にFMA命令に置き換えてくれるような賢い動作をします。
cargo run --releaseしかし、Rustの f64::mul_add は、ターゲットCPUがハードウェア命令としてのFMA(Fused Multiply-Add)をサポートしていないと判断された場合、C言語の標準ライブラリ(libm)の fma 関数を呼び出すようになっています。これにより、
let p_poly = (((((A[6] * x2 + A[5]) * x2 + A[4]) * x2 + A[3]) * x2 + A[2]) * x2 + A[1]) * x2 + A[0];
のようにべた書きするとちゃんとFMA命令でコンパイル。mul_addだとlibmでエミュレートされることとなり、逆に遅くなるという逆転現象が起きます。
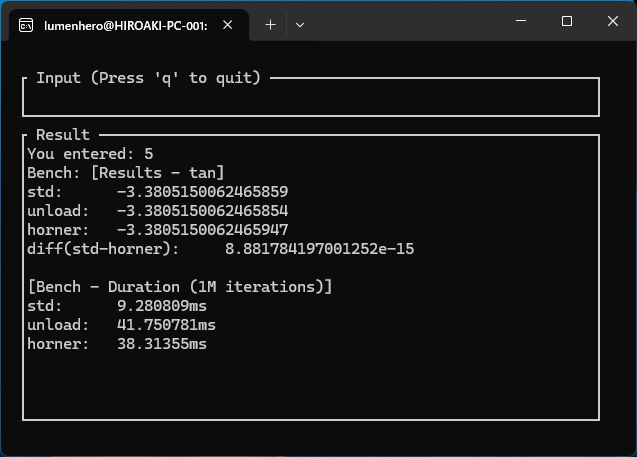
libmを呼び出しで遅くなった例
これの対策としては、実行するCPUの命令セットをフルに使っていいよと明示的に指定する必要があったりします。
RUSTFLAGS="-C target-cpu=native" cargo run --releaseまとめ
今回の最適化で、\(\tan\) の核となる多項式計算は極限まで高速化されました。しかし、計測の結果、全体の処理時間の 8 割以上が Payne-Hanek 法による範囲還元(大きな \(x\) を \(\pi/4\) 以内に収める処理) に費やされていることが判明しました。
範囲還元は精度を担保しつつ高速にしようとするとテーブル定義を行いショートカットするなどの工夫が考えられますが、実装が大変で今後の実装との兼ね合いもあるので、いったんは保留することにします。
次回は、sin、cos、tanと三角関数を実装してきたのでこれまでの振り返りとまとめを行いたいと思います。
次回:【Rustで作る電卓】三角関数をフルスクラッチまとめ 三角関数の実装(7) #24
ここまで読んでいただきありがとうございます。
では、次の記事で。 lumenHero
関連記事
以下の記事を読めば、自力で三角関数の電卓を実装できます。
シンプルなsinの実装と課題 : 【Rustで作る電卓】sin関数実装 Rustで挑む三角関数の実装(1) マクローリン展開と範囲還元 #18
余角とcosの実装: 【Rustで作る電卓】cos関数実装 Rustで挑む三角関数の実装(2) マクローリン展開と範囲還元 #19
前回 tanの実装:【Rustで作る電卓】ランベルト(Lambert)の連分数展開でtan(正接)を実装 三角関数の実装(5) #22
ほかの関数の実装
第11回 平方根の計算実装:【Rust自作TUI電卓】mod.rsを活用したスマートなモジュール管理と基本数学関数の実装 #11
第14回 ハレー法による立方根:【Rust自作TUI電卓】ニュートン法を超えろ!ハレー法による立方根(cbrt)の極限最適化 #14