0. はじめに
今回は、前回まで解説してきたリードソロモン符号とガロア体の演算を用いて、実際の文字列「HELLO」を対象として、バージョン2・誤り訂正レベルQの形式に合わせてQRコードのデータ領域(ビット列)を作り出していく「エンコード」の具体的な手順を追ってみようと思います。
本記事だけでも読めるように構成していますが、リードソロモン符号やガロア体の仕組みから知りたい方は、過去記事もあわせて読むと理解しやすくなります。
第1回:QRコードを解読する:エラーはどうやって直る?リード・ソロモン符号の基本 【第1回】

参考資料:リードソロモンエンコード:Github
今回の記事で紹介するプログラムは以下で公開しています。
リンクを開き、ページ上部の「Open in Colab」ボタンを押せば、Googleアカウントがあればブラウザ上で実際に動かして試すことができます。

Qr from Scratch:Step1 QR Encoder
QRコードの車輪の再発明をしながらQRコードを深く理解する。QRコードのエンコードを手順を追いながら試せます。
github.comgithub link : Qr from Scratch : Encoder
(https://github.com/Tsukumo-999/qr-code-from-scratch/blob/master/Step1/Hello_Encode.ipynb)
画像0-1 githubでの表示とcolabで開くボタン
1. QRコードのエンコードの手順概要
まず具体的な計算に入る前にQRコードのエンコードの流れをまとめました。
【前処理】【データコード語作成】【リードソロモン符号の計算】【画像にする】の4つのステップです。
- 【前処理】フォーマットや文字数を表すヘッダーと、埋め込む文字列(word)を2進数として用意する(asciiやutf-8などでエンコード(2進数に変換)する)
- 【データコード語作成】ヘッダーとword、および終端パターン(0000)をくっつけてメッセージ列を作る。そして、QRコードのフォーマットに合わせて文字数調整を行いデータコード語(16進数)を作成する。
- 【リードソロモン符号の計算】データコード語に対して、QRコードの誤り訂正レベルに合わせて作った生成多項式を用いて、リードソロモン符号の計算を行い、データコード語に付加する。
- 【画像にする】QRコードの規格に合わせて、固定部分(ファインダパタンやアライメントパタン)などに加えて、先の過程で計算したデータコード語を埋め込み、マスク処理をして完成!
QRコードはこれらのステップを以て、エンコードされます。以降、“HELLO”という文字列をQRコードにする手順とその流れを順に追っていきます。(githubにて公開している.ipynbファイルにて実行できます)
2. 前処理(データビットの生成と整形)
今回は、ちょうどいいサイズと誤り訂正レベルのバージョン2、誤り訂正レベルQのQRコードを作成します。
この規格では、QRコード全体のデータ容量は44バイトですが、レベルQではそのうち半分にあたる22バイトを誤り訂正(リードソロモン符号)のために使います。つまり、私たちが文字列を入れられる「最大データ容量」は22バイト(176ビット)となります。
QRコードのバージョンとは?:QRコードのバージョンとレベルとマスクパタン JIS0510の定義【QRコードを解読する 第4回】
ヘッダーとデータビットの作成
まずは文字列「HELLO」(5文字)を、コンピュータが扱いやすい2進数のデータ列に変換していきます。
- ヘッダーの作成どんな形式で何文字入っているかを示すヘッダーを作成します。
今回はバイトモード(0100)で、
文字数は5文字(2進数で00000101)なので、
ヘッダーは010000000101となります。 - 文字のデータ化「HELLO」を1文字ずつASCIIコードに変換し、8ビットの2進数にします
(例:’H’ -> 72 ->01001000)。 - 結合と終端パターンの追加ヘッダーとデータビットをくっつけ、データの終わりを示す終端パターン
0000を付加します。
ASCIIコード表
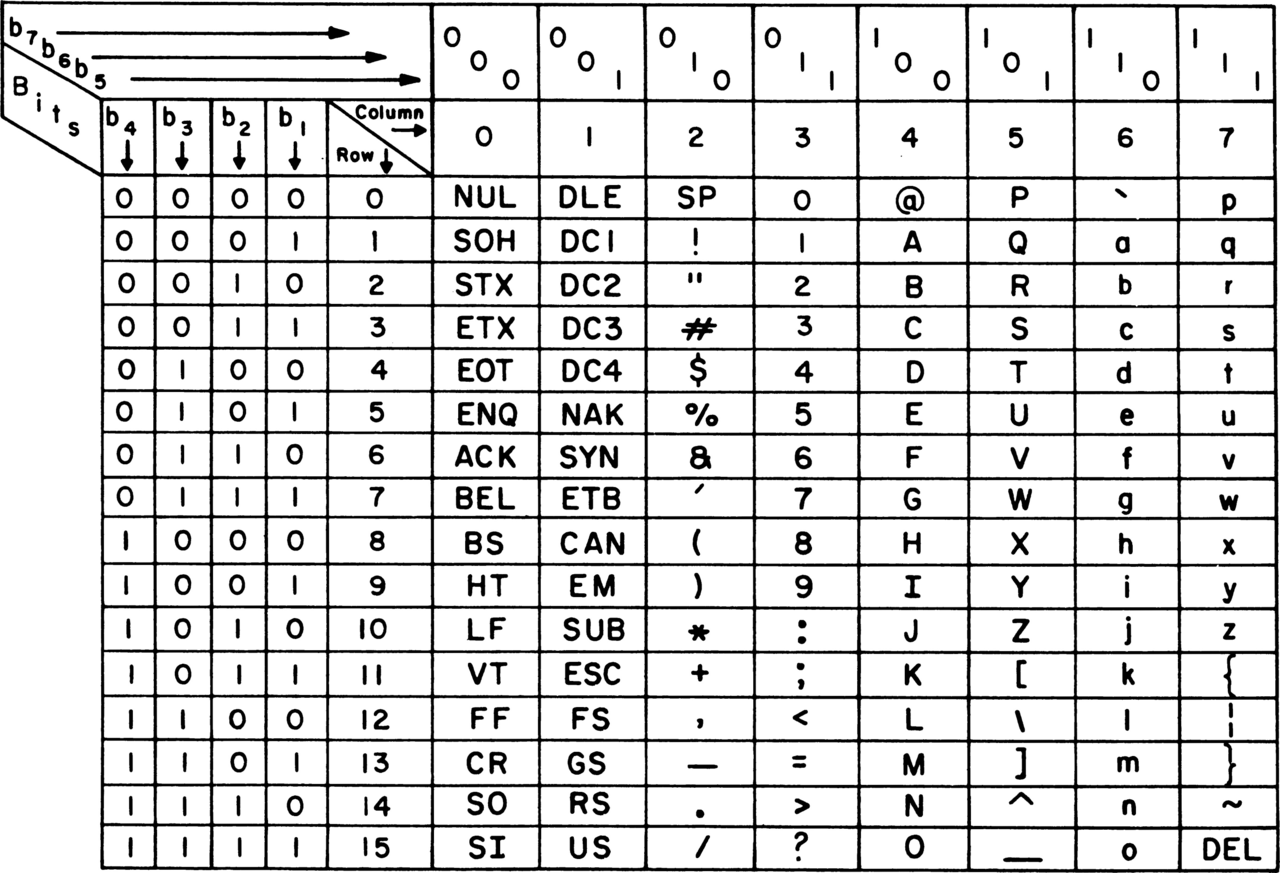
asciiコードの読み方:QRコードのリードソロモン符号 を計算してみる【QRコードを解読する 第3回】
埋め草(パディング)の追加
ここまでで作成したデータはまだ短く、最大容量の22バイトに達していません。QRコードの仕様では、空いたスペースを0で埋めてしまうと真っ白な領域ができて読み取りづらくなるため、「236 (11101100)」と「17 (00010001)」という2つの埋め草(パディングバイト)を交互に限界まで追加します。
最終的に完成した22バイトの「データコード語」は以下のようになります。
[64, 84, 132, 84, 196, 196, 240 , 236, 17, 236, 17, 236, 17, 236, 17, 236, 17, 236, 17, 236, 17, 236]
[---ここはデータ(HELLO)部分------,---ここからは埋め草部分-----> 3. リードソロモン符号の計算
データの準備ができたら、いよいよQRコードの肝である「誤り訂正コード」の計算です。
バージョン2・レベルQでは、22バイトのデータに対して、22バイトの誤り訂正コードを付加します。
- 生成多項式 \(G(x)\) の算出あらかじめ準備しておいたガロア体 GF(2^8) の演算テーブルを使い、22次の生成多項式 \(G(x)\) を計算します。これが割り算の「割る数」になります。
- メッセージ多項式の準備と割り算先ほど作った22バイトのデータコード語の後ろに、誤り訂正コードを入れるための「22個の0」をくっつけます(数式で言うと \(x^{22}\) を掛ける操作です)。これを生成多項式 \(G(x)\) で割る(筆算のようなXOR演算を繰り返す)と、「余り」として22バイトの誤り訂正コードが求まります。
データ部と誤り訂正部を合体させると、ちょうど規格の最大容量である44バイトの最終データ列が完成します。
3.1 22次の生成多項式
22次の生成多項式は初期値 1に対して (x – α^i) を掛けていく処理をすることで求まります。
前回や以前の記事で紹介した通りガロア体では加算と減算は同じ(XOR)であり、α^i は 前回(第5回)作成した 乗法表からexp_table[i] として取得可能です。
参考になる記事
第2回:デジタル世界の数学「ガロア体」を超ざっくり理解しよう!
デジタル世界の数学「ガロア体」を超ざっくり理解しよう!【QRコードを解読する 第2回】
前回:ガロア体 GF(2^8) の演算と乗法表の構築
QRコードの誤り訂正を支えるガロア体 GF(2^8) とは?乗法表の作り方と実装を解説【QRコードを解読する 第5回】
3.2 データコード語から生成多項式を用いてメッセージにする
前段で作成した「データコード語」と「生成多項式 \(G(x)\)」を使って、誤り訂正コード(メッセージ多項式の余り)を求めます。
数学的には「多項式の割り算」を行って「余り」を求める処理になりますが、言葉にするよりも実際のプログラムの流れを見た方が直感的に理解しやすいでしょう。処理の手順としては、「割り算の筆算」をプログラムで再現しているだけです。
各変数の説明
msg : 計算用のメッセージ配列(最終的にここに結果が残ります)data_codewords : データコード語(22byte長に整形した配列)num_ec_codewords : 22(誤り訂正コードの長さ。今回はバージョン2・レベルQなので22byte)G : 生成多項式 \(G(x)\) の各次の係数が入った配列
# ガロア体の掛け算の関数
# log_tableとexp_tableはあらかじめ計算しておく(第5回記事で作成したものと同じ)
def gf_mul(x, y):
"""ガロア体 GF(2^8) 上での乗算"""
if x == 0 or y == 0:
return 0
return exp_table[(log_table[x] + log_table[y]) % 255]
# 後ろに誤り訂正コードを入れるための「器(22個の0)」を用意
msg = data_codewords + [0] * num_ec_codewords
# メイン処理
for i in range(len(data_codewords)):
# 現在注目している先頭の係数
coef = msg[i]
# 係数が0なら、引く(XORする)必要はないのでスキップ
if coef != 0:
# G(x) の各項を coef 倍して、msg から引く(XOR)
for j in range(len(G)):
msg[i + j] ^= gf_mul(G[j], coef)
# ループ終了後、msg の前半(元データ部分)はすべて0になり、
# 後ろの22byte([0]で埋めた部分)に割り算の「余り」が残ります。
# これが求めていた「誤り訂正コード」です。
# 余り部分を抽出
ec_codewords = msg[-num_ec_codewords:]
# データコード語と誤り訂正コードを結合してメッセージ多項式(係数)を得る。
final_message = data_codewords + ec_codewords3.3 word : “HELLO”に対応するメッセージ多項式
上記プログラムを実行し、HELLOのメッセージ多項式を計算した結果が以下の通りです。
# 上位の22byteはデータコード語、下位22byteは誤り訂正(余り)
['0x40', '0x54', '0x84', '0x54', '0xC4',
'0xC4', '0xF0', '0xEC', '0x11', '0xEC',
'0x11', '0xEC', '0x11', '0xEC', '0x11',
'0xEC', '0x11', '0xEC', '0x11', '0xEC',
'0x11', '0xEC',
'0xED', '0xCE', '0xE5','0xEC', '0x3C',
'0xA1', '0x8D', '0x2E', '0x9E', '0x4D',
'0xA7', '0x3D', '0x68', '0x73', '0x0B',
'0x35', '0xFC', '0x3D', '0x09', '0x27',
'0xC6', '0x74']4. 画像にする(QRコードの組み立て)
データが完成したので、いよいよこれを2次元の「QRコード」の形に配置していきます。バージョン2のキャンバスサイズは 25×25 マスです。
4.1 固定パターンの配置
データを入れる前に、QRコードとして認識させるための「固定の目印」を配置します。
- ファインダパタン: 3つの角にある大きな四角。
- アライメントパタン: ズレ補正用の右下にある小さな四角。
- タイミングパタン: 白黒が交互に並ぶ縞模様。
- ダークモジュール: 必ず黒になる1マス。
- (フォーマット):QRのマスクがどんなパタンなのかなどの情報を入れる場所。後で入れるので今は場所確保だけしておく。
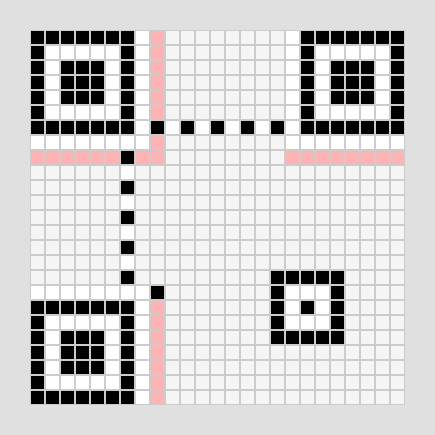
画像4-1 固定パタンを配置
(フォーマット情報が入る部分は薄い赤色で予約しています)
4.2 メッセージの流し込み
マスク情報などを入れる「フォーマット領域(予約領域)」を避けるように、右下から2列ずつ上・下へとジグザグに進むルートを計算します。
リードソロモン符号の復元性を生かすため、各バイトは固まって配置する必要があり、このような配置手法をとっています。

画像4-2 ジグザクにデータを割り当てするためのマップ
このルートに沿って、先ほど計算した44バイトの最終データ列を2進数(黒=1、白=0)として流し込んでいきます。
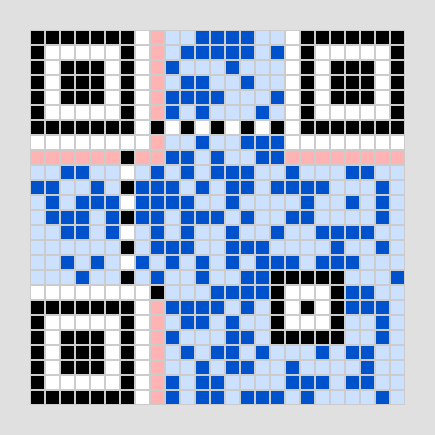
画像4-3 データを流し込む
4.3 仕上げ処理(マスクとフォーマット領域)
データを入れただけの状態だと、文字列によっては白や黒が偏ってしまい、スマホのカメラで読み取れなくなることがあります。
マスク処理(市松模様)
白黒の偏りをなくすため、全体に「マスク」をかけます。今回は最も美しい市松模様になる「マスクパターン000((x + y) % 2 == 0 のマスを反転)」を使用します。これを掛けると、データが均等に散らばってQRコードらしい見た目になります。(今回の例だとデータコード語の部分(右下あたり)を見るとわかりやすいと思います)
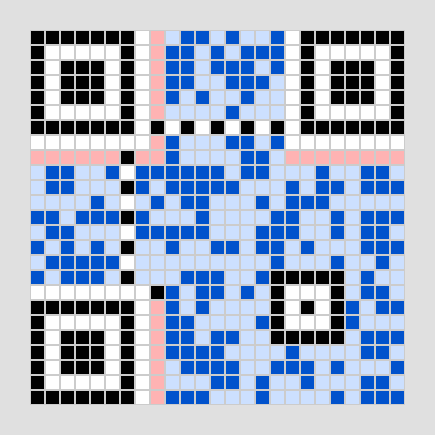
画像 4-4 市松模様で反転させるマスクを書けた後
マスクパタンはどのように選択される?
今回の実装では、今後のエンコードなどをわかりやすくするために市松模様に固定していますが、実際のQRコードでは、4つのペナルティルールの合計点が最も低いものを採用するという方式をとっています。
8つあるマスクパタンをそれぞれ試し、ペナルティパタン(検出精度が悪くなる可能性のあるパタン)をスコア化し、それが一番小さいものを選択します。
4つのペナルティルール
・ペナルティ1(N1):同色が長く連続している
・ペナルティ2(N2):大きな同色ブロック
・ペナルティ3(N3):ファインダパターンに似た並び
・ペナルティ4(N4):黒と白の割合が偏りすぎ
ペナルティの加算は、以下のように規格で定義されています。
N1 連続したセルが5つ以上の時、3を基本点として連続した分だけ加算する。 5個連続= 3点。6個連続 = 3 +1 =4点。
N2 \(2 \times 2\)以上の塊があるとき、そのサイズを\(m \times n\)とすると、N2 × (m – 1) × (n – 1)で減点します。(規格値 N2 = 3) もし、\(2 \times 2\)の塊があれば、 3 × 2 × 2 = 12 点。
N3 【検出のために特に重要】次回以降触れますが検出にはファインダパタンの検出精度が大きくかかわる為、これに似たパタンは大きく減点する必要があります。
ファインダパタンの並び ■ ☐ ■■■ ☐ ■ (1011101)があり、且つ前後に4セル以上(外枠の外もふくむ)の空白があると40点。(一番重いペナルティ)
N4 理想は白と黒50-50です。全モジュール中の黒の割合を求め、50%からどれだけ離れているかを5%単位で5%毎に10点。
このスコアの総計をもとに以下の8つから最適なマスクを選択します。

第4回 図2 QRコードのマスクパタン
引用元:JIS 0510[1]. p50 ,図21−1型シンボルに対するマスクパターンより引用
フォーマット情報の配置
最後に、空けておいたファインダパタンの周囲(フォーマット領域)に、「誤り訂正レベルQ」と「マスクパターン000」を使用していることを示す15ビットの情報を配置します。(ここでもBCH符号という誤り訂正の計算が行われています)。
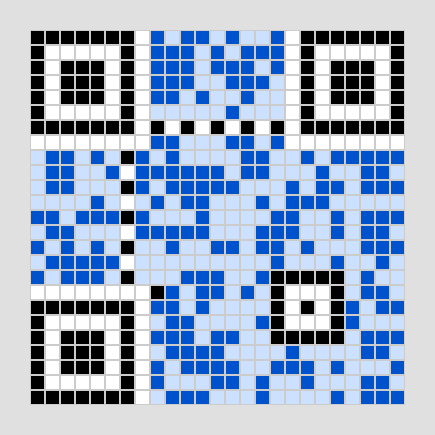
画像4-5 フォーマット情報を入れる
5. 完成!
これで全てのピースが埋まりました。周囲にクワイエットゾーン(余白)を設けて画像を出力すれば、本物のQRコードの完成です!

画像 5-1 QRコード : “HELLO”
Version 2, Level Q
お手持ちのスマートフォンで読み取れば、「HELLO」の文字が浮かび上がるはずです。
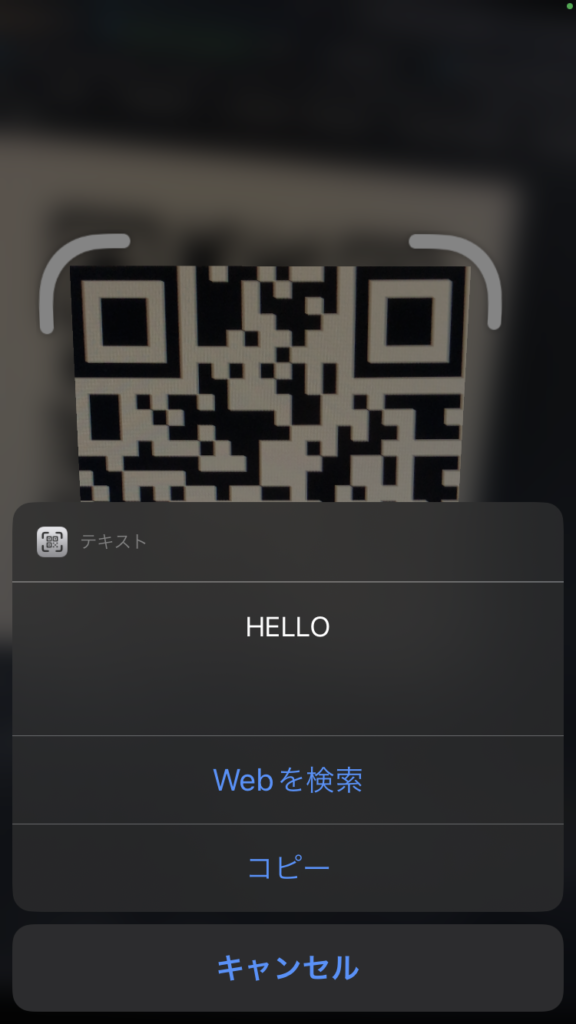
画像5-2 iphoneで読み取った結果
まとめと次回予告
今回は、過去5回にかけて解説してきたリードソロモン符号とガロア体およびQRコードのフォーマットをもとに、QRコードのエンコーダを自作しながら、その処理の流れを追ってみました。
これにて「エンコード編」は完結となりますが、完全なエンコードとデコードにはまだ道半ばです!
次回からは、いよいよ「デコード(復号)編」に突入します。 まずは今回作成した完璧なQRコードから文字列を抽出する「理想的な逆再生(Happy Path)」を体験し、その後、現実世界のカメラ越しでどうしても発生してしまう「ノイズ(汚れや欠損)」の壁に挑みます。
そして、本シリーズ最大のハイライトである「リード・ソロモン復号アルゴリズム(バーレカンプ・マッシー法やチェン探索など)」という数学的パズルを紐解き、傷ついたデータから執念で元の文字列を復元する「汎用デコーダ」の完成を目指します。
数学とビット演算の組み合わせが、日常のインフラを支えるいかに強固なシステムを作り上げているか、その鮮やかな裏側を一緒に暴いていきましょう!
次回:QRコードの「デコード」に挑む!完全なデータからの逆再生
関連記事は、2026年6月19日に公開予定 (あと7時間)
ここまで読んでいただきありがとうございます。では、次の記事で Lumen Hero.
関連記事
第1回:CRCと比較してリードソロモン符号の仕組みを大まかに理解する。
QRコードを解読する:エラーはどうやって直る?リード・ソロモン符号の基本 【第1回】
第2回:デジタル世界の数学「ガロア体」を超ざっくり理解しよう!
デジタル世界の数学「ガロア体」を超ざっくり理解しよう!【QRコードを解読する 第2回】
第4回:QRコードのバージョンとレベルとマスクパタン JIS0510の定義
QRコードのバージョンとレベルとマスクパタン JIS0510の定義【QRコードを解読する 第4回】
参考文献
- ガロア体入門 (Theoretical Background)https://theoretical-background.com/%E3%82%AC%E3%83%AD%E3%82%A2%E4%BD%93%E5%85%A5%E9%96%80/
- 日本工業規格 , X 0510:2018 (ISO/IEC 18004:2015) https://kikakurui.com/x0/X0510-2018-01.html