0. はじめに
前回の「エンコード編」では、リードソロモン符号とガロア体の演算を用いて、「HELLO」という文字列から実際にQRコードの画像を生成する手順を解説しました。
今回はいよいよ「デコード(復号)編」に突入します! まずは、生成したばかりの汚れや破損が一切ない完璧なQRコード画像から、元の文字列「HELLO」を抽出する「理想的な逆再生(Happy Path)」を体験してみましょう。エンコードの逆の手順を追うことで、QRコードの構造がよりくっきりと見えてくるはずです。

参考資料:サンプルQRデコーダ (Happy Path):Github
今回の記事で紹介するプログラムは以下で公開しています。
リンクを開き、ページ上部の「Open in Colab」ボタンを押せば、Googleアカウントがあればブラウザ上で実際に動かして試すことができます。

Qr from Scratch:Step2 QR Decoder (Happy Path)
QRコードの車輪の再発明をしながらQRコードを深く理解する。QRコードのデコードについて手順を追いながら試せます。
github.comgithub link : Qr from Scratch : Decoder (Happy Path)
(https://github.com/Tsukumo-999/qr-code-from-scratch/blob/master/Step2/Hello_Decode_happy_path.ipynb)
1. QRコードのデコード手順概要
デコードは、基本的にエンコードと真逆のステップを踏んで進みます。
- 【画像からの抽出】 カメラ等で読み取った画像を処理し、白黒のマス目を0と1の「2次元配列(行列)」に変換する。
- 【フォーマット情報の解析とマスク解除】 盤面からマスクの種類と誤り訂正レベルを読み取り、データ領域の白黒反転(マスク)を解除。その後、1次元のビット列として回収する。
- 【リードソロモン符号での検証】 ビット列をバイト(コード語)に変換し、ガロア体の演算を用いてデータにエラー(破損)がないか「シンドローム」を計算して検証する。
- 【データの解析と復元】 ヘッダー情報を読み解き、2進数のデータを元の文字列に復元する。
今回は理論の解説に集中するため、あらかじめバージョン2(25×25マス)であることが分かっている前提で進めます。
2. 画像から2次元配列(行列)への復元
まずは、スマートフォンのカメラ等で読み取った画像を、コンピュータが計算しやすい「0と1の数字の羅列」に変換します。
2.1 ファインダパタンの検出と画像の補正
QRコードの3つの角にある大きな四角(ファインダパタン)を検出し、画像が斜めに歪んでいても真っ直ぐな正方形になるように補正(透視変換)を行います。

画像2-1 ファインダパタン検出と補正
2.2 ビットマップ(2次元配列)の取得
真っ直ぐになった画像から、1マス(モジュール)ごとに中心の色をサンプリングします。
規格上、白は「0」、黒は「1」として25×25の2次元配列に格納します。これで、画像処理の段階からデータ処理の段階へと移行できました。

画像2-2 セルを読み取る
(わかりやすくするため、白と読み取れたところには赤丸、
黒と読み取れたところには青丸を描画しています。)
// 読み取れたビットマップ
// control + f で1を検索(ハイライト)すると、ファインダパタンなどが確認できます。
【抽出された2次元配列 (0:白, 1:黒)】
[1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1]
[1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1]
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1]
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1]
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1]
[1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1]
[1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1]
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1]
[0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0]
[0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1]
[0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0]
[1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1]
[0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0]
[1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1]
[0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0]
[1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1]
[1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0]
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1]
[1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0]
[1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1]
[1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0]
[1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1]3. フォーマット情報の取得とマスク解除
盤面が0と1の配列になったら、次はそのデータが「どのようなルールで配置されているか」を読み取ります。
3.1 フォーマット情報の抽出と復元
QRコードには、左上のファインダパタンの周囲と、右上・左下のファインダパタンの隣の計2箇所に、全く同じフォーマット情報(15ビット)が記録されています。2箇所を読み取って比較することで、汚れによる読み間違えを防ぎます。
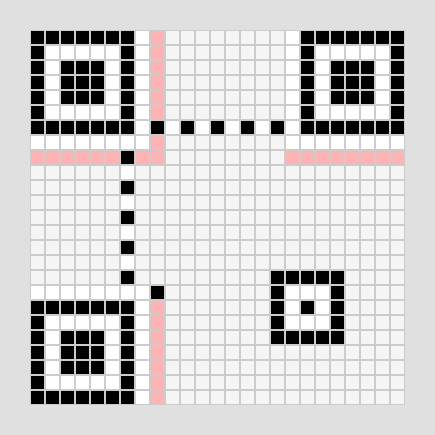
画像 3-1 フォーマット情報の格納位置

画像 3-2 前回作った対象となるqrコード
フォーマット情報は同じものを2つ配置しているので、読み取ったフォーマット情報は以下の通りです。
【2.1 フォーマット情報の抽出】
抽出したフォーマット情報1: 011010101011111
抽出したフォーマット情報2: 011010101011111
実際のqrでは、ロバストにするためこの二つのうち片方が欠損していても復元できるように設計されています。
この読み取った15ビットには、読み取り精度を上げるための固定マスク(101010000010010)が掛かっているため、これをXOR(排他的論理和)して解除します。
【解析結果】
- マスク解除後のデータ:
11000 - 上位2ビット(
11):誤り訂正レベル Q - 下位3ビット(
000):マスクパターン番号 0
3.2 マスクパターンの種類
エンコード時に白黒の偏りをなくすために掛けられた「マスク」の種類が判明しました。QRコード規格では以下の8種類のマスクが定義されています。
今回読み取ったマスクパターン番号は 0 なので市松模様であることがわかります。
表3-1: QRコードのマスクパタンの種類と条件
| マスク番号 (2進数) | 適用される条件式 (x:列, y:行) | パターンの特徴 |
000 | (x + y) % 2 == 0 | 市松模様(今回使用) |
001 | y % 2 == 0 | 水平の縞模様 |
010 | x % 3 == 0 | 垂直の縞模様 |
011 | (x + y) % 3 == 0 | 斜めの縞模様 |
100 | (y // 2 + x // 3) % 2 == 0 | 大きめの市松模様 |
101 | ((x * y) % 2) + ((x * y) % 3) == 0 | 複雑なパターン1 |
110 | (((x * y) % 2) + ((x * y) % 3)) % 2 == 0 | 複雑なパターン2 |
111 | (((x + y) % 2) + ((x * y) % 3)) % 2 == 0 | 複雑なパターン3 |
3.3 データ領域のマスク解除とジグザグスキャン
マスクパターンが「000(市松模様)」だと分かったので、ファインダパタンなどの予約領域を避けながら、データ領域全体にもう一度同じ条件でXOR演算を行います。これでデータの白黒反転が元に戻り、純粋なデータが盤面に現れます。
// マスク(市松模様)を外したビットマップ
// control + f で1をハイライトすると、ファインダパタンなどが確認できます。
【抽出された2次元配列 (0:白, 1:黒)】
[1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1],
[0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0],
[0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1],
[0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1],
[0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0],
[1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1],
[0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0],
[1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0],
[1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1],
[1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0],
[1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1]これと、前回作成したときに出てきたマスクをかける前のQRコートを比較すると、一致することを確認できます。
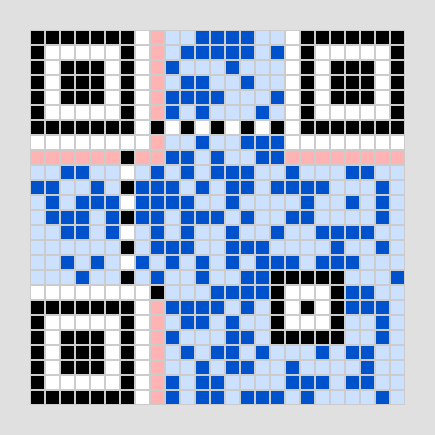
画像 3-3 エンコード中マスク前のqrコード
その後、右下からスタートして上・下へとジグザグに進みながら、1マスずつデータを回収します(ジグザグスキャン)。バージョン2の場合、回収されたビット列はちょうど 359ビット になります。
// 読み取ったセルのbitを並べた
// 01:は連番のバイト番号です。
// 8 [bit]* 44 + 7 [bit]= 352 [bit]+ 7 [bit]= 359 [bit]
01: 01000000 02: 01010100 03: 10000100 04: 01010100 05: 11000100
06: 11000100 07: 11110000 08: 11101100 09: 00010001 10: 11101100
11: 00010001 12: 11101100 13: 00010001 14: 11101100 15: 00010001
16: 11101100 17: 00010001 18: 11101100 19: 00010001 20: 11101100
21: 00010001 22: 11101100 23: 11101101 24: 11001110 25: 11100101
26: 11101100 27: 00111100 28: 10100001 29: 10001101 30: 00101110
31: 10011110 32: 01001101 33: 10100111 34: 00111101 35: 01101000
36: 01110011 37: 00001011 38: 00110101 39: 11111100 40: 00111101
41: 00001001 42: 00100111 43: 11000110 44: 01110100 45: 00000004. リードソロモン符号での検証と復元
ここからがガロア体と多項式の出番です。
4.1 バイト(コード語)への変換
回収した1次元のビット列を先頭から8ビット(1バイト)ずつ区切って数値化します。
バージョン2・レベルQの総容量は44バイトなので、前半の22バイトを「データ部」、後半の22バイトを「誤り訂正部(パリティ)」として分割します。
// ビット列からコード語(バイト)への変換
▼ データ部 (22バイト) ▼
[64, 84, 132, 84, 196, 196, 240, 236, 17, 236, 17, 236, 17, 236, 17, 236, 17, 236, 17, 236, 17, 236]
▼ 誤り訂正部 (22バイト) ▼
[237, 206, 229, 236, 60, 161, 141, 46, 158, 77, 167, 61, 104, 115, 11, 53, 252, 61, 9, 39, 198, 116]4.2 シンドローム(エラーの兆候)の計算
受信した44バイトのデータを、ひとつの巨大な多項式 \(R(x)\) とみなします。
エンコード編で作成したガロア体 GF(2^8) の演算テーブルを使い、この多項式に \(\alpha^0, \alpha^1, \dots, \alpha^{21}\) を代入して、結果が「0」になるかを確認します。この代入して得られた結果をシンドロームと呼びます。計算には本サイトの計算機実装シリーズでおなじみ、ホーナー法という効率的なアルゴリズムを使用します。
【検証結果】
- 計算された22個のシンドローム:
[0, 0, 0, ..., 0] - 検証成功! すべてのシンドロームが0でした。これは、データに一切の破損がない(エンコード時と全く同じである)ことを証明しています。
参考:ホーナー法
ホーナー法とは?多項式計算の効率化手法そのメリットとデメリット
5. データの解析と文字列の復元
破損がないことが確認できたので、あとは前半22バイトの「データ部」をルールに従って翻訳するだけです。データ部の後方には、エンコード時に限界まで詰め込んだ「埋め草(236 と 17)」が入っているため、必要な文字データだけを先頭から抜き出します。
5.1 ヘッダーの読み取り
先頭のデータには「どんな文字の種類か(モード)」と「何文字入っているか」が記録されています。
▼ データ部 の先頭部分 (埋め草削除後)▼
[64, 84, 132, 84, 196, 196, 240]表5-1: データモードの指示子と対応
| 指示子 (4ビット) | モード名 | 格納されるデータの種類 |
0001 | 数字モード | 0〜9の数字のみ |
0010 | 英数字モード | 数字、大文字英字、一部の記号 |
0100 | バイトモード | 8ビット単位のデータ(ASCII, UTF-8, Shift_JIS等) |
1000 | 漢字モード | Shift_JISを用いた全角文字 |
【今回の解析結果】
- モード指示子: 先頭4ビットが
0100→ バイトモード - 文字数指示子: 次の8ビットが
00000101→ 5文字
5.2 文字列へのデコード
データコード語の部分を取り出したいのでヘッダー部分を除きます。
// 元の先頭部分 [64, 84, 132, 84, 196, 196, 240 ... ]
64 = 01000000
84 = 01010100
132 = 10000100
84 = 01010100
196 = 11000100
196 = 11000100
240 = 11110000
//連結とヘッダーの該当部分
0100 00000101 01001000010001010100110001001100010011110000
mode| Mojisuu
// データコード語部分
01001000010001010100110001001100010011110000
// 1byteごとに区切れば
抽出したデータバイト列: [72, 69, 76, 76, 79]「バイトモードで5文字」と分かったので、続くデータを8ビットずつ5回切り出します。
切り出された数値 [72, 69, 76, 76, 79] を文字コード表(ASCIIコード)と照らし合わせると……
復元成功:「HELLO」
6. まとめと次回予告
完璧なQRコードから、見事に元の文字列「HELLO」を抽出することができました!
エンコードで行った「マスク処理」や「生成多項式による計算」を、順序立てて紐解いていくことで、パズルが解けるように元のデータが浮かび上がる気持ちよさを体感できたのではないでしょうか。
しかし、これはあくまで汚れや欠損が一切ない「Happy Path」のお話です。
現実世界でカメラ越しに読み取るQRコードには、どうしても光の反射や汚れによる「ノイズ(読み取りエラー)」が発生します。もし、先ほどの「シンドローム」の中に一つでも「0ではない数字」が現れたら……?
次回にいきなり、デコードの全容を詳しく1度に説明すると読みづらくなってしまう(1万語を優に超える)ため、デコードにひつような理論や定理などを簡単な例を用いながら1つずつ説明して、最後にデコーダを実装していこうと思います。
次回:シンドローム計算
QRコードを読み解く:シンドロームの計算とエラー検出【QRコードを解読する 第8回】